Détection d’activité - Analyse d’une courbe de charge
Sommaire
- 1. Motivations
- 2. Les techniques de résumés automatique
- 3. Les Transformers
- 4. Le modèle CamemBERT
- 5. Le modèle mBART'hez
- 6. La métrique d’évaluation
- 7. POC CamemBERT pour le résumé extractif
- 8. Données et Data Labelling process (DLP)
- 9. Entraînement
- 10. Evaluation du modèle
- 11. Résultats
- 12. Description de la Web App
- 13. Identification des besoins
- 14. Architecture de la Web App
- 15. Choix techniques
- 16. Workflow de l’application
1. Motivations
Les modèles s’appuyant sur une architecture à base de « Transformer », tel que BERT, permettent d’ouvrir les champs des possibilités en terme traitement du langage naturel. En effet des modèles pré-entrainés sur un corpus français tel que {Camem,Flau}BERT fournissent des performances bien meilleures pour l’ensemble des tâches NLP (tâches FLUE) que les modèles de référence BERT multilingue (mBERT).
2. Les techniques de résumés automatique
« Résumer un texte est un processus complexe qui consiste à se mettre à la place de l’auteur et reprendre en son nom l’argumentation en la réduisant au quart des mots utilisés. » Lorsque l’on résume un texte, il est important de conserver les éléments informationnels clés et le sens du contenu. Etant donné que le résumé manuel de textes est une tâche coûteuse en temps et généralement laborieuse, l’automatisation de cette tâche gagne en popularité et constitue donc une forte motivation pour la recherche universitaire. De nombreuses applications liées au traitement automatique du langage naturel ont vu le jour comme par exemple, la génération automatique de titres, résumé de textes juridiques, classification de textes, reconnaissance d’entités nommées…
Il s’avère que résumer un texte est un processus complexe et compliqué à entreprendre pour un humain. Pour produire un résumé, l’humain doit d’abord avoir une compréhension fine des sujets abordés dans le texte d’origine. Pour faciliter la réalisation de cette tâche et surtout ne pas oublier les éléments informationnels importants, l’humain peut avoir recours à la technique du surlignage pour faire ressortir les phrases clés du texte. Or, les machines n’ont pas les mêmes capacités cognitives et connaissances linguistiques qu’un humain pour identifier les éléments clés dans le texte à résumer. On s’aperçoit donc que même pour un humain, le résumé de textes est une tâche complexe et non triviale.
Notre première étude s’est donc intéressée aux différentes façons de résumer un texte. L’objectif est ici de cerner les différentes techniques de résumé qu’il existe et de les comparer entre-elles. Globalement, il existe 3 façons de résumés du texte qui sont les suivantes
2.1. Le résumé extractif
Le résumé extractif consiste à extraire des séquences de mots voir même des phrases entières en fonction de leur importance dans le texte d’origine. On peut comparer cela à une personne qui surligne les extraits les plus révélateurs d’un texte.
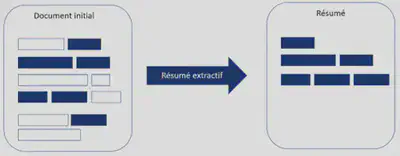
La réalisation d’un résumé extractif s’effectue en 3 étapes :
La construction d’une représentation intermédiaire du texte à résumer. Pour cela, il existe différentes méthodes « bas niveau » adoptant une approche très statistique et calculatoire comme par exemple la technique de représentation du sujet ou la représentation des indicateurs. Il existe également des méthodes « haut niveau » basées sur des architectures de Deep Learning du type
Transformers. Nous reviendrons en détail juste après sur chacune de ces techniques.L’attribution d’un score pour chacune des phrases, on appelle cela du « sentence ranking »
La construction du résumé en sélectionnant les $N$ meilleures phrases avec le plus haut score
Nous allons passer en revue chacune de ces 3 étapes.
Etape 1: Construction de la représentation intermédiaire du texte à résumer
Il existe deux approches différentes pour générer une représentation intermédiaire d’un texte. Il convient maintenant de les expliquer en détail :
1ère approche : La représentation du sujet vise à représenter les sujets majeurs abordés dans le texte en calculant les fréquences d’apparition des mots et utiliser un seuil de fréquence pour trouver le mot qui peut potentiellement décrire au mieux un sujet. Pour ce faire, différents algorithmes peuvent être employés.
- Probabilité de mot : Cet algorithme utilise simplement la fréquence des mots comme indicateur de l’importance du mot. La probabilité d’un mot $w$ est donnée par la fréquence d’occurrences du mot, $f(w)$, divisée par tous les mots de l’entrée qui a un total de $N$ mots.
TF-IDF (Term Frequency Inver Document Frequency): L’algorithmeTF-IDFest perçu comme étant une avancée de la méthode probabilité de mot. En clair, l’algorithme attribue de faibles poids aux mots qui apparaissent très fréquemment dans la plupart des documents car ils sont considérés comme étant des mots ayant peu de valeurs informatives. A l’inverse, il accorde un poids plus élevé aux termes apparaissant peu dans le corpus. Cette méthode est généralement utilisée pour extraire l’importance d’un terme $i$ dans un document $j$ par rapport au reste du corpus, à partir d’une matrice d’occurrences $mots \times documents$. Ainsi, pour une matrice $T$ de $|V|$ termes et $D$ documents : $$ \text{TF}(T, w, d) = \frac{T_{w,d}}{\sum_{w'=1}^{|V|} T_{w',d}} $$
2ème approche : La représentation des indicateurs décrit chaque phrase comme une liste de caractéristiques formelles (indicateurs) d’importance telles que la longueur de la phrase, la position dans le document. En d’autres termes, elle vise à représenter le texte en fonction d’un ensemble de fonctionnalités et à les utiliser pour classer directement les phrases sans représenter les sujets du texte d’entrée. On distingue les méthodes suivantes :
- Méthodes graphiques : La méthode utilise l’algorithme
TextRankpour représenter les documents sous forme de graphe connexe. Les phrases forment les sommets et les arêtes entre les phrases indiquent à quel point les deux phrases sont similaires. La similitude de deux phrases est mesurée à l’aide de la matrice similitude cosinus. Si elle est supérieure à un certain seuil, ces phrases sont liées. Cette représentation graphique aboutit à deux résultats : les sous-graphiques inclus dans le graphique créent des sujets abordés dans les documents et les phrases importantes sont identifiées. Les phrases qui sont connectées à de nombreuses autres phrases dans un sous-graphique sont susceptibles d’être le centre du graphique et seront incluses dans le résumé. Les étapes du fonctionnement de l’algorithmeTextRanksont comme suit :- Représenter chaque phrase du texte sous la forme d’un vecteur grâce à la technique du « Word-embeddings ». Le vecteur est calculé selon plusieurs caractéristiques propres à chaque phrase comme la longueur, la position dans le document…
- La similarité entre les vecteurs est calculée en mesurant le cosinus de l’angle entre chaque paire de phrases vectorisées. Plus l’angle est petit, plus la similitude cosinus est élevée. Ce dernier est stocké dans une matrice que l’on appelle matrice de similarité.
- L’algorithme convertit ensuite la matrice de similarité en un graphe connexe dans lequel les phrases forment les sommets et les scores de similarité forment les arêtes pour le calcul du rang de la phrase.
- Les $N$ phrases ayant les meilleurs rangs sont ajoutées au résumé final.
- Méthodes graphiques : La méthode utilise l’algorithme
- Apprentissage automatique : les méthodes d’apprentissage automatique abordent le problème de la synthèse comme un problème de classification. Les modèles essaient de classer les phrases en fonction de leurs caractéristiques en phrases résumées ou non résumées. Pour l’entraînement des modèles, nous disposons d’un ensemble de documents accompagné de leurs labels (valeurs cibles à prédire) qui correspondent à un résumé extractif réalisé par un humain. Cela forme alors le dataset d’entraînement. Celui-ci, une fois annoté, différents algorithmes peuvent être employés comme l’arbre de décision, les SVM, et le K-Means. Pourtant, le problème avec les classifieurs est que si nous utilisons des méthodes d’apprentissage supervisées pour la synthèse, nous avons besoin d’un ensemble de documents étiquetés pour former le classifieur, cela implique, la construction d’un corpus. Dans l’ensemble, les méthodes d’apprentissage automatique se sont avérées très efficaces et fructueuses dans la synthèse de documents uniques et multiples, en particulier dans les résumés spécifiques, tels que le résumé d’articles scientifiques ou le résumé biographique.
Nous venons de voir les différentes techniques de représentation intermédiaire du texte pour la synthèse extractive. L’avantage des méthodes graphiques et des méthodes basées sur la probabilité des mots est que ces dernières ne nécessitent pas de traitement linguistique spécifique à la langue. Cela signifie que ces méthodes peuvent être appliquées à différentes langues. Ces méthodes sont appelées des méthodes « bas niveau » car elles adoptent des approches très calculatoires pour identifier les sujets importants d’un texte. En revanche, ces méthodes sont moins efficaces que les techniques d’apprentissage automatique. Nous verrons par la suite que de nouveaux modèles d’apprentissage automatique basés sur une architecture « Transformer » ouvrent les champs des possibilités dans le domaine du traitement automatique du langage naturel.
Etape 2: Sentence Ranking
Lorsque la représentation intermédiaire est générée, un score d’importance est attribué à chaque phrase. Pour les représentations de sujet, le score d’une phrase dépend des mots de sujet qu’elle contient, et pour une représentation d’indicateur, le score dépend des caractéristiques des phrases. Autrement dit, dans les approches de représentation de sujet, le score d’une phrase représente dans quelle mesure la phrase explique bien certains des sujets les plus importants du texte. Dans la représentation des indicateurs, le score est calculé en agrégeant les preuves issues de différents indicateurs pondérés.
Etape 3: Sélection des $N$ phrases
Pour finir, le système de synthèse sélectionne les $N$ phrases les plus importantes pour produire un résumé. Certaines approches utilisent des algorithmes gourmands pour sélectionner les phrases importantes et elles peuvent convertir la sélection de phrases en un problème d’optimisation où une collection de phrases est choisie, compte tenu de la contrainte qu’elle doit maximiser l’importance, la cohérence globale et minimiser la redondance.
2.2. Le résumé abstractif
Le résumé abstractif consiste à sélectionner des mots en fonction de leur compréhension sémantique, même si ces mots n’apparaissaient pas dans les documents sources. De manière plus concrète, cela revient à utiliser des techniques avancées de langage naturel pour interpréter et examiner le sens du texte et reproduire les points clés avec de nouveaux mots.

Les méthodes abstractives se distinguent des méthodes extractives car les mots ou phrases présents dans le résumé généré ne sont pas forcément issus du texte original. La métaphore que l’on pourrait associer à ces méthodes est celle d’un lecteur qui lit un texte entièrement avant d’en produire le résumé qu’il écrira lui-même à la main, avec ses propres mots et structures de phrase. Le résumé de texte abstractif est une tâche de sequence to sequence, aussi appelée Seq2Seq, comme d’autres tâches telles que la traduction, la réponse aux questions (question answering).
Dans la quasi-totalité des cas, une architecture de type encodeur-décodeur est utilisée. L’encodeur calcule une représentation intermédiaire numérique des informations contenues dans le document à résumer. Afin de réaliser cette opération, des réseaux de neurones peuvent être utilisés et bien sûr, les modèles doivent pouvoir prendre en entrée des séquences. Des réseaux de neurones récurrents sont utilisés comme par exemple des LSTM ou GRU qui transmettent un état caché (représentation) d’une cellule à une autre comme illustré ci-dessous:
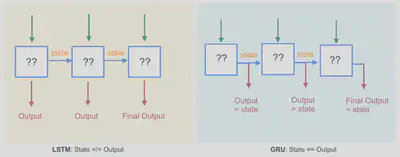
Cependant ces méthodes “traditionnelles” ne sont plus à l’état de l’art et aujourd’hui, les modèles de type « Transformers » que je détaillerai plus tard sont utilisés.
Une fois la représentation du document calculée, un décodeur interprète cette représentation et effectue la tâche finale qui peut se présenter sous la forme d’une classification, génération de textes…
2.3. Le résumé hybride
Les méthodes hybrides exploitent des stratégies mixtes qui combinent la méthode extractive et abstractive. L’algorithme doit décider quel mode de résumé doit être employé pour y couvrir les sujets importants abordés dans le texte.
Les résumés purement extractifs donnent souvent de meilleurs résultats par rapport aux résumés abstractifs. Cela est dû au fait que les méthodes abstraites font face à des problèmes telles que la représentation sémantique, l’inférence et la génération du langage naturel, qui sont relativement plus difficiles à mettre en œuvre que les approches basées sur les données telle que l’extraction de phrases. Aussi, les résumés extractifs sont plus complets que les résumés abstractifs mais ils ont pour inconvénient d’être plus longs. Cependant, avec les dernières avancées dans le domaine du Deep Learning, certains modèles sont maintenant capables de modéliser le langage naturel rendant ainsi la méthode de résumé abstractif de plus en plus performante. L’idée alors d’une méthode hybride tirant profit des méthodes extractives et abstractives prend donc tout son sens. Néanmoins, il existe également un problème non résolu associé à la combinaison de l’extraction et de l’abstraction après l’étape de sélection du contenu. Ce problème est dû au fait que cette combinaison peut altérer la cohérence du résumé. Un facteur déterminant le taux de mélanges d’abstraction et d’extraction judicieusement choisi pourrait pallier en partie à ce problème de cohérence du résumé. Les méthodes hybrides en sont encore à leurs balbutiements. De futurs travaux scientifiques sont nécessaires pour exploiter pleinement le potentiel d’une combinaison harmonieuse de ces deux méthodes. J’ai donc décidé de poursuivre mes recherches sur la méthode extractive, car c’est une technique qui a fait ses preuves et sur la méthode abstractive car elle présente un fort potentiel grâce à l’avènement du Deep Learning.
3. Les Transformers
Aujourd’hui, en machine learning, parmi les architectures les plus courantes et celles qui produisent les performances à l’état de l’art sont basées sur des Transformers et le mécanisme d’attention. En effet, l’architecture « Transformer » s’est imposée comme le modèle de référence pour l’ensemble des champs d’application du NLP (classification de texte, question answering,..). Avant l’arrivée des « Transformers » en 2017, les réseaux RNN étaient utilisés pour comprendre un texte. Ces réseaux RNN prennent en entrée une séquence (une phrase) puis traitent les mots de manière séquentielle c’est-à-dire les uns après les autres. Cela permet au RNN de connaître la position d’un mot dans une phrase. Cependant les RNN ont du mal à gérer de grandes séquences de texte (les paragraphes). Cela signifie que lorsque le réseau a fini de traiter 90% des mots de la longue séquence, ce dernier oublie les mots qu’il a examinés au début de la séquence. A cela s’ajoute un autre problème qui concerne l’apprentissage compliqué des RNN à cause de la disparition du gradient (non-convergence vers le minimum global de la fonction de perte). Aussi, étant donné que les RNN fonctionnent de manière séquentielle, il n’est pas possible de paralléliser les calculs sur plusieurs GPU (carte graphique) pour diminuer le temps d’entraînement du réseau. Cela signifie donc qu’il n’est pas envisageable d’entraîner le réseau RNN sur un grand volume de données.
Tous ces problèmes constituent en fait les principales motivations de l’introduction des Transformers. En effet, les scientifiques en imaginant l’architecture « Transformer » ont pu apporter une solution plus efficace que les RNN. Autrement dit, si celle-ci a fait l’objet de notre attention, c’est que ce modèle est à la fois :
- Plus performant que les RNN en termes de résultats pour diverses tâches NLP
- Plus performant que les RNN en termes de rapidité d’apprentissage, car l’entraînement peut être parallélisé
- Dépasse les limitations des RNN en termes de longues dépendances temporelles.
- Une fois pré-entraîné, de façon non supervisée (initialement avec un très large dataset constitué de nombreux documents), il possède une “représentation” linguistique qui lui est propre. Il est ensuite possible, sur la base de cette représentation initiale, de le personnaliser pour une tâche NLP particulière. Il peut être entraîné en mode incrémental (de façon supervisée cette fois) pour spécialiser le modèle rapidement et avec peu de données. Même si nous pouvons référencer et représenter la signification de chaque mot avec un vecteur, la vraie signification d’un mot repose sur le contexte dans la phrase, car le même mot dans différentes phrases peut avoir des significations différentes. Les questions qui se posent alors sont : Comment le Transformer gère-t-il l’ordre des mots sans RNN ? Comment le Transformer parvient à modéliser le langage naturel ? Pour répondre à ces questions, il convient de passer en revue l’architecture d’un Transformer et d’expliquer ce qui se cache derrière le mécanisme d’attention qui constitue la pierre angulaire de l’architecture.
3.1. Architecture d’un transformer
Intéressons-nous d’abord à l’architecture globale du Transformer. Elle est décrite comme ci-dessous :
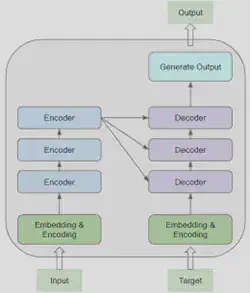
Son architecture est construite comme suit :
Un bloc “Embedding & Encoding” est connecté à l’entrée de la pile d’encodeur et décodeur. Cette couche transforme les mots de la séquence d’entrée en vecteur pour qu’ils soient compris par l’encodeur et le décodeur. Ces derniers pourront alors effectuer des opérations calculatoires sur ces vecteurs pour y déceler les mots de la séquence d’entrée ayant une signification voisine. A cela s’ajoute un encodage positionnel qui permet au Transformer de gérer l’ordre des mots dans une phrase et ainsi comprendre le contexte global de la séquence d’entrée.
Une pile d’encodeurs : Chaque encodeur prenant en entrée la sortie de l’encodeur précédent sauf le premier qui prend en entrée les mots vectorisés et encodés par encodage positionnel.
Une pile de décodeurs : Chaque décodeur prenant en entrée la sortie du décodeur précédent et la sortie du dernier encodeur sauf pour le premier décodeur qui ne prend en entrée que la sortie du dernier encodeur.
En résumé, un Transformer est composé de blocs d’encodeurs et de décodeurs dont chacun possède sa propre matrice de poids. A cela s’ajoute un bloc transformant la séquence d’entrée dans un format qui peut être ingéré par les blocs encodeurs et décodeurs. Intéressons-nous maintenant à ce que contient un bloc encodeur et décodeur.

Chaque encodeur contient la couche d’auto-attention qui permet d’examiner de manière sélective chaque mot de la séquence d’entrée. C’est cette couche qui modélise les relations qui existent entre les mots d’une phrase. Enfin, l’encodeur contient également une couche complètement connectée appelée Feed-Forward. Celle-ci a pour but de connecter les couches de réseaux de neurones de chaque encodeur entre elles.
Côté décodeur, ces derniers suivent la même configuration que l’encodeur à savoir une couche d’auto-attention et une couche Feed-Forward. En revanche, le décodeur intègre une deuxième couche d’attention appelée attention encodeur-décodeur qui permet de communiquer au décodeur le degré d’importance qui a été accordé à chaque mot par l’encodeur dans une phrase à l’aide d’un vecteur de contexte.
Le schéma global d’un Transformer peut paraître effrayant, or l’innovation derrière le Transformer se résume en trois concepts principaux :
- L’encodage positionnel
- L’attention
- L’auto-attention
3.2. Le mécanisme d’attention
Lorsque l’on regarde un match de football à la télévision, on focalise instinctivement notre attention sur le ballon car notre expérience nous a appris que c’est proche du ballon que se trouve l’essentiel de l’information de l’action de jeu en cours. Des systèmes de traduction ou des descriptions d’images parviennent aujourd’hui à simuler ce genre de mécanisme pour améliorer leurs performances. On appelle cela le mécanisme d’attention qui tend à se rapprocher du mécanisme inspiré du fonctionnement du cortex cérébral.
Par exemple, dans le cadre d’une traduction automatique, l’attention permet au modèle de « regarder » chaque mot de la phrase d’origine lorsqu’il prend une décision sur la façon de traduire les mots dans la phrase de sortie.
La clé des performances du Transformer se trouve dans l’utilisation du mécanisme d’attention. Pour expliquer cela, partons d’abord d’un exemple :
- Le chat a bu le lait car il avait faim
- Le chat a bu le lait car il était sucré
Dans la première phrase, le mot il se réfère à « chat ». A l’inverse dans la deuxième phrase le mot il fait référence au mot lait. Le rôle de l’attention est donc d’examiner la phrase de manière sélective en trouvant les bonnes associations de mots.
En fait, pour expliquer de façon imagée, l’attention construit une sorte de carte thermique qui indique sur quel mot de la phrase d’entrée, le modèle doit se concentrer lorsqu’il génère chaque mot en sortie. En entraînant un Transformer, ce dernier apprend à partir de données, sur quel mot il doit porter une attention particulière. Par exemple, l’encodeur communique une information au décodeur comme : “les mots 8, 11 et 23 sont très importants pour donner le sens exact de cette phrase. De plus, il faudra combiner ou corréler 8 et 11, retiens bien ça au moment de décoder la phrase”. En revanche, cela dépend de la position des mots dans la phrase et de leur position les uns par rapport aux autres pour créer un contexte. C’est grâce à l’encodage positionnel que la similarité entre les mots d’un point de vue sémantique peut être vraiment prise en compte. Finalement, l’attention combinée à l’encodage positionnel permet ainsi au modèle de comprendre le sens d’une phrase.
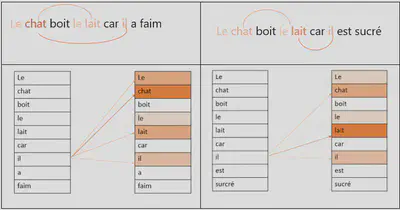
De manière plus concrète, le mécanisme d’attention relie l’encodeur et le décodeur. Son but est de représenter le degré d’attention accordé aux mots à l’aide du vecteur de contexte. Il permet d’informer le décodeur sur quels mots de la séquence d’entrée se rapportent le plus au mot qu’il est en train de générer en sortie, soit qu’ils s’y rapportent comme contexte pour lui donner un sens, soit qu’ils s’y rapportent comme mots “cousins” de signification proche. Le mécanisme d’attention consiste finalement à pondérer l’importance des mots en calculant une loi de probabilité concernant les mots du texte source. Le décodeur se réfère simplement à cette distribution pour prédire le mot suivant qu’il doit générer. Nous ne retrerons pas dans les détails mathématiques sur le calcul du degré de l’attention mais celui repose sur une formule mathématique composé d’une paire clé (key) valeur (value) répondant à une requête (query).
4. Le modèle CamemBERT
Le modèle CamemBERT est la version française du modèle BERT, pré-entraîné sur un large corpus français de 138 GB. Ce dernier repose sur une architecture « Transformer » de type BERT. BERT est l’un des modèles basés sur des Transformers le plus populaire. Il utilise un tokenizer « Sentence Piece » qui découpe une phrase en plusieurs segments de phrase à l’aide de l’algorithme Byte Pair Encoding. Pour apprendre à modéliser la langue française, le modèle a été entraîné à prédire des mots préalablement masqués dans une phase. Ce modèle est particulièrement adapté pour la tâche de synthèse extractive.
Exemple :
[CLS]indique un début de séquence[SEP]une séparation, en général entre deux phrases dans notre cas.[MASK]un mot masqué qui correspond au mot à prédire
La séquence d’entrée suivante a été volontairement supprimée d’un mot, le mot « masqué », et le modèle va apprendre à prédire ce mot masqué.
- Entrée =
[CLS]l’homme est allé[MASK]magasin[SEP] - Entrée =
[CLS]l’homme est[MASK]au magasin[SEP]
5. Le modèle mBART’hez
Le modèle BART’hez est la version française du modèle BART, pré-entraîné sur un large corpus français de 120 GB. Ce dernier repose sur une architecture auto-encodeur basée sur des Transformers. Il peut être considéré comme un mélange entre BART et CamemBERT. En effet, l’architecture BART utilise un encodeur de type BERT, ce qui permet d’extraire le contexte dans les deux directions, la sortie de cette première partie est envoyée dans un décodeur autorégressif (un GPT constitué uniquement d’un décodeur) afin de prédire le token suivant. Pour apprendre à modéliser le langage naturel, le modèle a été entraîné à débruiter du texte précédemment altéré avec une fonction arbitraire (permuter les mots, masquer un mot, supprimer un mot, …). Ce modèle est particulièrement efficace pour faire de la génération de texte (Sequence To Sequence).
Etant donné ses bonnes capacités à générer du texte, ce modèle sera utilisé pour la tâche de résumé abstractif.
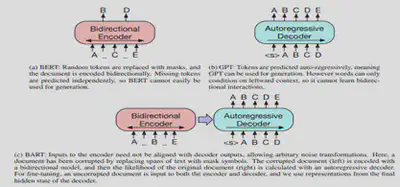
Au-delà du fait que les deux modèles reposent sur une architecture à base de Transformer, il existe plusieurs points communs entre ces deux modèles qui sont les suivants :
- Utilisent le mécanisme d’attention pour analyser de manière sélective la séquence d’entrée (une phrase) et comprendre la sémantique de celle-ci.
- Capables de modéliser la langue française et d’avoir une connaissance fine de la grammaire française.
- Peuvent être adaptés pour réaliser différentes tâches NLP :
- Classification de texte
- Traduction
- Comparer le sens de deux phrases et dire si elles sont équivalentes
En revanche, à la différence de BERT qui utilise un modèle de type Transformers bidirectionnels (analyse la séquence d’entrée dans les deux 2 sens gauche et droite), les modèles GPT sont basés sur des Transformers left-to right. GPT est un modèle constitué uniquement de décodeurs. Chaque cellule de Transformer ne pose son attention que sur celles qui sont à sa gauche. A la différence de l’encodeur, le décodeur est autorégressif, c’est-à-dire qu’en plus de prendre en entrée les données, il a aussi en « input » les différentes valeurs précédemment générées.

6. La métrique d’évaluation
J’ai choisi d’évaluer nos modèles de résumé de textes avec la métrique ROUGE. Il s’agit de la métrique de base la plus couramment utilisée dans les publications scientifiques pour évaluer la qualité d’un résumé de manière automatisée.
Recall-Oriented Understudy for Gisting Evaluation - ROUGE (Lin, 2004) est un ensemble de métriques pour évaluer le résumé automatique de textes longs composés de plusieurs phrases ou paragraphes. ROUGE comprend un grand nombre de variantes distinctes, y compris huit méthodes de comptage de n-grammes différentes pour mesurer le chevauchement de n-grammes entre le texte généré et le texte de base (écrit par un humain). En simplifiant la notation de l’article original (Lin, 2004), $ROUGE-N$ peut être défini comme suit :
Un version plus explicite de la formule serait celle-ci:
$$ ROUGE-n = \frac{{\sum_{i=1}^{N} \text{Overlap}(n) }}{{\sum_{i=1}^{N} \text{Reference-Length}}} $$- $Overlap(n)$ : est le nombre de n-grammes communs entre le résumé généré et la référence
- $Reference-Length$ : Reference-Length est la longueur totale de la référence
- $N$ : $N$ est le nombre total de résumés évalués
Où $\sum n$ fait la somme de tous les n-grammes de longueur n (par exemple, si $n=2$), la formule mesure le nombre de fois où un bi-gramme correspondant est trouvé dans l’hypothèse (générée par le modèle) et le texte de référence (généré par l’homme). S’il y a plus d’un résumé de référence, la sommation externe ($\sum r$) répète le processus sur tous les résumés de référence.
ROUGE est bon pour évaluer l’adéquation entre le résumé et le texte d’origine mais a du mal à évaluer la fluidité ou la factualité, car il ne fournit pas d’informations sur le flux narratif, la grammaire ou le flux thématique du résumé. Il n’évalue pas non plus l’exactitude factuelle du résumé par rapport au corpus à partir duquel il est généré.
Il existe plusieurs variantes du Score ROUGE qui sont les suivantes :
- $ROUGE - 1$ : Fait référence au chevauchement uni-grammes (chaque mot) entre le résumé généré par le modèle et les résumés de référence.
- $ROUGE - 2$ : Fait référence au chevauchement bi-grammes (mots réunis par 2) entre le système et les résumés de référence.
- $ROUGE - L$ : Statistiques basées sur la plus Longue Séquence Commune (LCS).
Pour chaque métrique $ROUGE-n$ est calculé :
- $f = f-score$ : moyenne harmonique entre la précision et la valeur de rappel. Plus le niveau de score est élevé, plus le résumé a des chances d’être bon. La valeur du score
ROUGEdans les papiers scientifiques correspond pour la plupart du temps à la valeur f-score.
- $p = précision$ : le pourcentage de mots présents dans le résumé de référence également présents dans le résumé généré. Par exemple, pour une recherche du texte sur un ensemble de documents, la précision est le nombre de résultats corrects divisée par le nombre de tous les résultats renvoyés. La précision répond à la question : « Combien d’éléments sélectionnés sont révélateurs ».
$$ \text{Précision} = \frac{\text{Documents pertinents} \cap \text{Documents récupérés}}{\text{Documents récupérés}} $$
$r = rappel$ : le pourcentage de mots présents dans le résumé généré également présents dans le résumé de référence. Par exemple, pour une recherche du texte sur un ensemble de documents, le rappel est le nombre de résultats corrects divisé par le nombre de résultats qui auraient dû être renvoyés. Le rappel répond à la question : « Combien d’éléments révélateurs sont sélectionnés » .
$$ \text{Recall} = \frac{\text{Documents pertinents} \cap \text{Documents récupérés}}{\text{Documents pertinents}} $$7. POC CamemBERT pour le résumé extractif
On sait que le modèle CamemBERT, puisqu’il est pré-entraîné, contient déjà une représentation linguistique assez fine de la langue française. Mais le modèle n’est pas capable de produire des résumés de qualité. Le premier objectif de ce POC sera d’entraîner le modèle sur la tâche de synthèse extractive. Une fois l’entraînement du modèle terminé, le second objectif sera d’évaluer via la métrique ROUGE, la performance du modèle sur la tâche de résumé extractif et de comparer cette dernière aux méthodes de résumés extractifs traditionnelles TF-IDF et K-Means.
8. Données et Data Labelling process (DLP)
En général, la plupart des modèles NLP sont pré-entraînés sur la langue anglaise. Par conséquent, les datasets dédiés aux entraînements des modèles de résumés automatiques sont en anglais. J’ai besoin de collecter et/ou fabriquer nos propres jeux de données. En effet, les données sont le nerf de la guerre en machine learning, sans celles-ci, les résultats obtenus seraient médiocres. Dans le papier scientifique : MLSUM: The Multilingual Summarization Corpus rédigé par des chercheurs du CNRS, j’apprend qu’il n’existe pas actuellement de large dataset en langue française pour la tâche de résumé. Pour répondre à cette problématique, les chercheurs ont construit le dataset ML SUM.
Le dataset ML SUM constitue alors mon premier jeu de données avec lequel je pourrai spécialiser le modèle sur la tâche de résumé extractif. Cependant, le dataset ML SUM n’a pas été conçu pour la tâche de résumé extractif. En effet, ce dataset a été labellisé par des humains. Cela signifie donc que les résumés sont construits à partir de nouvelles phrases et non de phrases clés extraites directement du texte source. Ce dataset n’est pas approprié pour le fine-tuning de notre modèle CamemBERT sur la synthèse extractive.
J’ai identifié un autre dataset supplémentaire à celui de ML SUM ; il s’agit du dataset Reddit. L’inconvénient de ce dataset est qu’il n’est pas labellisé. Cependant, je pense que ce dataset est idéal pour entraîner le modèle CamemBERT sur la tâche de résumé extractif. En effet, celui-ci étant constitué de multiples petites conversations (issues du forum de discussions Reddit), il s’agit du dataset se rapprochant le plus des données textuelles que l’on peut recueillir lors d’une réunion ; à savoir des échanges de paroles entre plusieurs personnes. L’inconvénient de ce dataset est que ce dernier est au format XML et n’est pas directement utilisable par le modèle. Il est donc nécessaire de « parser » le document pour récupérer le texte brut.
| Dataset | Description | Information technique | Labélisation | Lien |
|---|---|---|---|---|
| ML Sum | Un jeu de données de résumé multilingue à grande échelle. Obtenu à partir de journaux en ligne, il contient plus de 1,5m million de paires article/résumé dans cinq langues différentes. | Disponible depuis l’API HuggingFace, Découpé en 3 parties : Train : 392 902 textes, Validation : 16 059 textes, Test : 15 828 textes | OUI mais ce ne sont pas des résumés extractifs | Lien |
| Reddit est un corpus de dialogue français qui contient une riche collection de conversations écrites spontanées entre humains, extraites du jeu de données public de Reddit disponible via Google BigQuery. | Le dataset est composé de 556.621 conversations avec 1.583.083 énoncés au total. L’archive spf.tar.gz contient les discussions Reddit dans un fichier XML, Le dataset est découpé en 3 parties : Train : 417 466 textes, Validation : 69 576 textes, Test : 69 578 textes | NON | Lien |
Nous venons donc de voir qu’en l’état, les datasets ne sont pas exploitables par le modèle. De plus, ces modèles ne sont pas labellisés pour la synthèse extractive. Un pré-traitement des données est donc nécessaire pour d’une part transformer les données dans un format compréhensible par le modèle et d’autre part automatiser la labellisation des données. Pour automatiser la labellisation des datasets, il est nécessaire d’utiliser des méthodes de « bas niveau » qui sont indépendantes de la langue. Ainsi, j’ai fait le choix d’extraire les phrases via deux méthodes de résumés extractifs très populaires pour générer des résumés. Celles-ci utilisent la technique représentation du sujet pour sélectionner les phrases à extraire :
TF-IDF : J’ai appliqué TF-IDF sur les textes afin de calculer les scores associés à chacune des phrases pour pouvoir extraire les plus intéressantes d’entre elles. J’ai choisi de labelliser les datasets avec l’algorithme TF-IDF car il est rapide à mettre en œuvre.
K-Means : La seconde méthode que j’ai appliquée est l’algorithme des K-Means (ou k-moyennes en français) qui est un algorithme de clustering qui permet de classifier les phrases dans plusieurs groupes représentant les différents sujets abordés dans le texte. Ensuite, les scores sont calculés en mesurant la distance des phrases par rapport au centroïde du cluster auquel elles appartiennent. Ainsi, les phrases les plus proches du centroïde sont plus représentatives du sujet courant.
Processus de labellisation du dataset ML SUM
Le dataset ML SUM contient 1.5 millions de paires article/résumé dans cinq langues différentes. Dans le cadre de notre projet, j’ai travaillé avec la partie française. Le dataset a été découpé en 3 parties distinctes (Train, Test, Validation) pour l’entraînement et l’évaluation du modèle. Ensuite, les algorithmes de labellisation ont été appliqués. De manière générale, je me suis aperçu que le résumé généré par l’algorithme K-Means est beaucoup plus long que celui généré par TF-IDF. En effet, le texte généré par K-Means ne peut pas être considéré comme un véritable résumé au sens de la définition que j’ai établi au début de ce rapport, soit un quart au maximum des mots utilisés par rapport au texte d’origine.
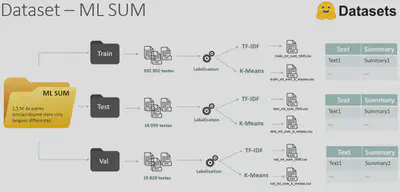
Processus de labellisation du dataset REDDIT
Le dataset REDDIT est composé de 556 621 petites conversations spontanées issues du forum REDDIT au format XML. Pour extraire le texte des balises XML, le parser python lxml est utilisé. De plus, un important nettoyage de données a été appliqué pour supprimer tous les caractères spéciaux (émoticônes, ponctuations répétitives, …) contenus dans les différentes conversations. Comme pour le dataset ML SUM, une fois les données parsées et nettoyées, le dataset a été découpé en 3 parties distinctes (Train, Test, Validation). Je me suis aperçu que le label correspond à un « copier-coller » du texte à résumer. Il se trouve que les textes à résumer sont beaucoup trop petits (4 phrases maximum). Or par défaut, l’algorithme TF-IDF extrait au minimum les 3 premières phrases clés du texte d’origine. Cela rend le dataset peu pertinent pour fine-tuner le modèle CamemBERT sur la tâche de synthèse extractive. Ayant pris connaissance de ce résultat, j’ai jugé contre-productif de poursuivre le processus de labellisation des données avec l’algorithme K-Means car cela amènerait au même résultat. Le dataset REDDIT ne sera donc pas utilisé pour « fine-tuner » le modèle CamemBERT car le processus de labellisation ne donne pas le résultat escompté.

9. Entraînement
Pour l’entraînement du modèle, j’ai utilisé la librairie PyTorch, qui est un framework open source dédiée à la conception de modèle de Deep Learning. L’avantage de PyTorch est qu’il met à disposition une très grande quantité de fonctionnalités avec des calculs qui peuvent être accélérés grâce aux cartes graphiques CUDA Nvidia sur lesquelles je donnerai plus de détails par la suite.
En plus de ces frameworks, j’ai utilisé la librairie Huggingface, qui contient de nombreux outils qui permettent d’accélérer la mise en place et l’utilisation de modèles Transformer. Ainsi, il a été possible de récupérer très simplement en quelques lignes de codes, le modèle CamemBERT pré-entraîné. Cette libraire intègre également la métrique d’évaluation ROUGE.
Le pré-entraînement d’un tel modèle coûte très cher en temps et en argent (plusieurs milliers d’euros en fonction du dataset et de la taille du modèle). Bien évidemment, former un modèle à partir de zéro conduit à de meilleurs résultats, mais cela implique un coût financier plus important. Dans le cadre de ce projet, je n’avais pas les moyens d’entraîner depuis le début (from scratch) le modèle. Heureusement, le modèle CamemBERT est déjà pré-entraîné.
À l’heure actuelle, il n’existe pas de version du modèle CamemBERT spécifique à la tâche de résumé extractif. J’ai donc réalisé par moi-même l’entraînement du modèle sur cette tâche.
Apprentissage par transfert : Le fine-tuning
Pour spécialiser le modèle CamemBERT sur la tâche de résumé extractif, j’ai effectué un fine-tuning de ce dernier afin de le rendre performant sur cette tâche. Avant d’expliquer la démarche que j’ai mise en œuvre pour entraîner le modèle, il convient d’expliquer ce qui se cache derrière le fine-tuning.
L’apprentissage par transfert (Transfert Learning en anglais) se produit lorsqu’un modèle développé pour une tâche est réutilisé pour travailler sur une deuxième tâche. Le réglage fin (fine-tuning en anglais) est en fait une approche de l’apprentissage par transfert. Dans un Transfer Learning, nous entraînons le modèle avec un ensemble de données et ensuite, nous entraînons le même modèle avec un autre ensemble de données qui a une distribution de classes différentes que dans l’ensemble de données d’entraînement. Cette technique permet de transférer la connaissance acquise sur un jeu de données “source” pour mieux traiter un nouveau jeu de données dit “cible”. Le Transfer Learning peut s’expliquer intuitivement à travers un exemple simple : imaginons une personne qui veuille apprendre à jouer du piano, elle pourra plus facilement le faire si elle sait déjà jouer de la guitare. La personne pourra capitaliser sur ses connaissances musicales déjà acquises dans la pratique du piano pour apprendre à jouer un nouvel instrument.
Dans un Fine-tuning, qui est une approche de Transfer Learning, nous avons un ensemble de données avec lequel nous réalisons 90% de l’entraînement du modèle. On obtient ainsi un modèle pré-entraîné. Ensuite, nous terminons l’entraînement du modèle à savoir les 10% restants avec un autre dataset spécifique à la tâche sur laquelle le modèle doit performer. Le fine-tuning a pour but d’ajuster très finement les poids du réseau de neurones pour pouvoir affiner le modèle sur une tâche NLP bien spécifique. En effet, le taux d’apprentissage choisi pour un fine-tuning est plus faible que celui d’un entraînement classique de manière à minimiser les impacts sur le poids des couches de réseaux de neurones déjà ajustées.
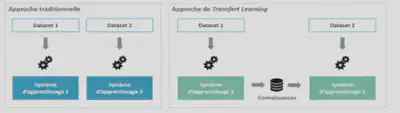
Fine-tuning de CamemBERT avec HuggingFace
Le modèle CamemBERT est volumineux. Il possède 110 millions de paramètres. Par conséquent, pour pouvoir réaliser le fine-tuning dans des délais convenables, il est nécessaire d’accélérer les calculs en tirant profit de la puissance de la carte graphique de la machine Aubay. Mon ordinateur est équipé d’un GPU RTX 2080 avec 8 Go de VRAM (mémoire virtuelle). Malheureusement, la taille de la mémoire vidéo de ma carte graphique n’est pas suffisante pour réaliser le fine-tuning du modèle CamemBERT.
La plupart des frameworks de Machine Learning intègrent nativement l’utilisation de l’accélération graphique, notamment avec les cartes du fabricant NVIDIA. Cela est possible grâce à toute une pile logicielle et physique allant du matériel à l’appel des fonctions, comme schématisée ci-dessous :

Cette pile est composée tout d’abord du matériel qui est le GPU installé dans la machine. Sur cette machine fonctionne un système d’exploitation, Windows ou Linux. Dans notre cas, chez Aubay, nous utilisons Windows. Afin que l’OS (Operating System) puisse reconnaître et communiquer avec le matériel, il est nécessaire d’installer le pilote.
Les frameworks de machine learning comme Pytorch ou Tensorflow ne communiquent pas directement avec le pilote du GPU, des librairies viennent s’ajouter entre eux et le pilote afin d’avoir une couche d’abstraction et des fonctions de plus haut niveau.
Parmi ces librairies, on retrouve cuDNN (CUDA for Deep Neural Networks) pour l’accélération des calculs dans les réseaux de neurones profonds, ou encore NCCL pour la communication multi-GPU ou multi-node, mais aussi cuBLAS, pour l’accélération des calculs d’algèbre linéaire. C’est assez complexe d’installer correctement ces pilotes et librairies mais il est important de comprendre au minimum le fonctionnement de l’accélération des calculs. Si un maillon de la chaîne est défaillant, alors les frameworks ne fonctionnent pas correctement. Il faut notamment faire attention aux versions des librairies qui sont installées et si elles correspondent bien à celles exigées par le framework.
J’ai réalisé plusieurs essais afin de faire fonctionner l’entraînement de CamemBERT sur ma machine mais la plupart d’entre eux plantaient à cause de la trop petite quantité de mémoire mise à disposition par le GPU (8 Gb).
La très grande taille du modèle a rendu la tâche très difficile car il est impossible de le charger sur la carte graphique et donc d’accélérer les calculs sans réaliser de sacrifices sur le temps d’entraînement ou la précision des résultats. Pour pallier ce problème, j’ai alors utilisé plusieurs techniques afin de réduire la mémoire utilisée lors de l’entraînement :
La précision mixte : cette méthode consiste à stocker les flottants sur 16 bits plutôt que sur 32 bits pour certains calculs. Ainsi, cela permet de réduire un peu la mémoire utilisée sans trop impacter les résultats finaux car certains calculs n’ont pas forcément besoin d’une précision sur 32 bits.
L’accumulation du gradient : cette méthode consiste à diviser un batch (ensemble d’échantillons de données à passer dans le modèle en une fois) en plusieurs plus petits batchs puis à accumuler le gradient sur l’ensemble de ces “sous-batchs” avant de réaliser la mise à jour des poids du modèle. Par exemple, faire des mini-batchs de 4 éléments que l’on accumule 2 fois revient mathématiquement à calculer des batchs de 8 éléments. Cela permet de réduire la quantité de mémoire utilisée et de lancer l’entraînement, mais cela a pour conséquence d’allonger sa durée totale.
Pour établir la taille du lot d’entraînement (batch) optimal, j’ai décidé d’utiliser la même taille de batch que celle préconisée par les chercheurs qui ont conçu le modèle CamembertForClassification qui est le modèle CamemBERT de référence spécialisé pour la tâche de classification de textes. Le batch-size optimal est de 32. Cependant, la puissance de ma machine n’était pas suffisante pour lancer l’entraînement. Pour pallier ce problème, j’ai utilisé l’accumulation du gradient. Avec cette technique, j’ai pu découper le batch de 32 en 4 sous-batch que l’on accumule 8 fois. Ainsi j’ai pu entraîner le modèle avec un batch-size optimal et préserver la précision de ce dernier.
Lors d’un fine-tuning, il est essentiel de réduire le taux d’apprentissage pour ajuster les poids du modèle sans mélanger leur signification pour le réseau. Si on augmente le taux d’apprentissage, nous obtenons de mauvais résultats en raison du grand pas d’optimisation de la descente de gradient. Cela peut conduire à un état dans lequel le réseau de neurones ne peut pas trouver le minimum global mais uniquement local. Pour le fine-tuning, j’ai utilisé l’optimisateur Adam. Il s’agit de l’optimisateur le plus utilisé pour faire converger l’entraînement des modèles de Deep Learning. Le taux d’apprentissage que j’ai utilisé est $5e-5$.
En résumé pour économiser la mémoire du GPU, j’ai entrepris les actions suivantes :
- Utiliser un batch size plus petit
- Utiliser l’accumulation de gradient
- Fine-tuning en précision mixte
Impact des différents paramètres sur la mémoire du GPU :
| Taille d’un échantillon de données (batch-size) | Moyen |
|---|---|
| Optimisateur | Haut (fort impact sur les résultats) |
| Longueur de la séquence | Bas |
| Précision mixte | Haut |
Finalement, tout au long de cette expérience, j’ai dû évaluer et trouver le meilleur compromis entre les ressources et la consommation de temps afin de garantir la précision du modèle. Durée des entraînements :
| Configuration | ML-SUM labellisé par TF-IDF | ML-SUM labellisé par K-Means |
|---|---|---|
| CamemBERT Base | 20H | 42H |
10. Evaluation du modèle
Pour évaluer les performances du modèle CamemBERT « fine-tuné » avec le dataset ML-SUM, j’ai comparé le score ROUGE obtenu par mon modèle avec le score ROUGE obtenu par les méthodes de résumés extractifs traditionnelles, basées sur les statistiques et le modèle CamemBERT-Base + Kmeans Summarizer. Ce dernier utilise le modèle CamemBERT pour les incorporations de textes et le clustering K-Means pour identifier les phrases proches du centroïde pour la sélection des phrases à ajouter dans le résumé. Il a été développé par des enseignants-chercheurs avec comme objectif de fournir aux étudiants un outil capable de résumer le contenu des cours, en fonction du nombre de phrases souhaitées.
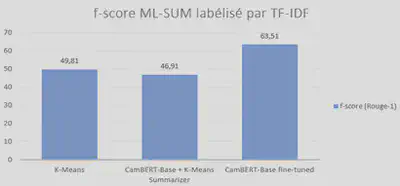
Résultats du Score ROUGE sur le dataset ML-SUM labellisé par TF-IDF
| Configuration | Rouge 1 (f-score) | Rouge 2 (f-score) | Rouge L (f-score) |
|---|---|---|---|
| TF-IDF | - | 49.82 | 36.80 |
| CamemBERT-Base + K-means Summarizer | 46.91 | 30.27 | 35.40 |
| CamemBERT-Base «fine-tuned» | 63.51 | 56.89 | 58.70 |
Résultats du Score ROUGE sur le dataset ML-SUM labellisé par K-Means
| Configuration | Rouge 1 (f-score) | Rouge 2 (f-score) | Rouge L (f-score) |
|---|---|---|---|
| K-means (benchmark) | 49.81 | 36.79 | 40.13 |
| CamemBERT-Base + K-means Summarizer | 45.01 | 33.21 | 36.88 |
| CamemBERT-Base «fine-tuned» | 39.10 | 30.02 | 31.56 |
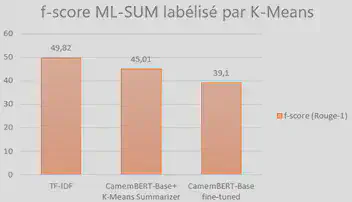
Comme prévu, les résultats obtenus par le modèle CamemBERT que j’ai « fine-tuné » avec le dataset ML-SUM labellisé par TF-IDF sont bons. En effet, le score ROUGE est bien meilleur que le score ROUGE obtenu par la méthode K-Means et le modèle CamemBERT-Base + K-Means. Par conséquent, le modèle CamemBERT « fine-tuned » est plus performant sur la tâche de résumés extractifs que les méthodes de résumés se basant uniquement sur la statistique et les probabilités de mots pour établir un résumé extractif. En revanche, le résultat obtenu par notre modèle « fine-tuné » avec le dataset ML-SUM labellisé avec K-Means obtient un score ROUGE plus faible. Le fine-tuning ne semble pas porter ses fruits sur ce jeu de données. Cela est dû probablement à la qualité des labels du dataset généré avec l’algorithme K-Means. En effet, nous avons vu avant que K-Means a généré des résumés qui sont beaucoup trop longs et ne s’apparentent donc pas comme un réel résumé qui synthétise les idées principales du texte d’origine en maximum 3-4 phrases comme cela est le cas pour le dataset ML SUM labellisé avec TF-IDF.
Les enseignements que j’ai pu tirer de cette expérience sont, que l’utilisation d’un modèle pré-entraîné dans une tâche similaire, donne de bons résultats lorsque nous utilisons l’apprentissage par transfert. Cependant, si nous ne disposons pas suffisamment de données dans le nouvel ensemble de données ou même si les hyperparamètres ne sont pas les meilleurs, nous pouvons obtenir des résultats insatisfaisants. J’ai pu m’apercevoir voir à quel point l’apprentissage automatique dépend toujours de son jeu de données et des paramètres du réseau. La qualité du dataset sur lequel est entraîné le modèle, joue un rôle important dans la précision du résultat que ce dernier va prédire.
11. Résultats
| Texte Source | Présent dans l’Aube mercredi, Emmanuel Macron a visité un gymnase de Pont-Sainte-Marie (Aube) pour marquer le début de la reprise des activités sportives. Arrivé aux côtés de Tony Parker et de la footballeuse Laure Boulleau, le chef de l’Etat a assisté à une animation de basket et présenté le « Pass Sport », une nouvelle aide pour les jeunes sportifs. Ce « Pass Sport », une aide de 50 euros par enfant, destiné aux familles qui perçoivent l’allocation de rentrée scolaire ou pour les enfants souffrant de handicap, aide à financer l’inscription dans un club affilié à une fédération – ou, dans les quartiers prioritaires de la ville, également à une association sportive. Au total, 5,4 millions d’enfants seront éligibles à cette aide, qui sera disponible à la rentrée. L’exécutif table sur un taux d’utilisation de 50 % environ et compte renouveler cette aide en 2022. Après cette rencontre, Emmanuel Macron s’est rendu au stade municipal pour assister aux entraînements des jeunes du FC Pont Sainte Marie, et discuter avec eux. Emmanuel Macron a rappelé que la crise sanitaire avait été particulièrement « dure » pour les jeunes, qui ont dû faire des « sacrifices » dans leurs activités notamment sportives, mais il s’est félicité d’avoir fait le choix de les « préserver (…) en ouvrant au maximum les écoles ». « Cette reprise, elle est extrêmement importante pour la santé de nos enfants », ainsi que l’alimentation, a-t-il aussi souligné. Via les diverses aides Covid, l’Etat a déjà déployé 3,5 milliards d’euros pour soutenir l’écosystème sportif, selon l’Elysée et 100 millions d’euros ont été budgétés pour ce nouveau dispositif. Ce qui apporterait déjà une grosse bouffée d’oxygène aux clubs, qui craignent de ne pas voir revenir leurs adhérents après la pandémie. Le chef de l’Etat a voulu montrer sa considération « pour un secteur dont il sait qu’il a été particulièrement affecté par la crise sanitaire », a souligné l’Elysée. C’est également un message en vue des Jeux olympiques 2024 qui auront lieu à Paris, qui doivent permettre à la France de développer la place du sport dans la société. « Cette reprise du sport est aussi le point de départ d’une nouvelle course de fond qui nous emmène jusqu’en 2024 », où l’objectif sera de « ramener le maximum de médailles », mais aussi de « vraiment faire de la France une nation sportive », a déclaré le président de la République. |
| K-Means | Au total, 5,4 millions d’enfants seront éligibles à cette aide, qui sera disponible à la rentrée. L’exécutif table sur un taux d’utilisation de 50 % environ et compte renouveler cette aide en 2022. Emmanuel Macron a rappelé que la crise sanitaire avait été particulièrement « dure » pour les jeunes, qui ont dû faire des « sacrifices » dans leurs activités notamment sportives, mais il s’est félicité d’avoir fait le choix de les « préserver (…) en ouvrant au maximum les écoles ». Ce qui apporterait déjà une grosse bouffée d’oxygène aux clubs, qui craignent de ne pas voir revenir leurs adhérents après la pandémie. « Cette reprise du sport est aussi le point de départ d’une nouvelle course de fond qui nous emmène jusqu’en 2024 », où l’objectif sera de « ramener le maximum de médailles », mais aussi de « vraiment faire de la France une nation sportive », a déclaré le président de la République |
| TF-IDF | Ce « Pass Sport », une aide de 50 euros par enfant, destiné aux familles qui perçoivent l’allocation de rentrée scolaire ou pour les enfants souffrant de handicap, aide à financer l’inscription dans un club affilié à une fédération – ou, dans les quartiers prioritaires de la ville, également à une association sportive. Emmanuel Macron a rappelé que la crise sanitaire avait été particulièrement « dure » pour les jeunes, qui ont dû faire des « sacrifices » dans leurs activités notamment sportives, mais il s’est félicité d’avoir fait le choix de les « préserver (…) en ouvrant au maximum les écoles ». |
| CamemBERT-Base + K-Means Summarizer | Présent dans l’Aube mercredi, Emmanuel Macron a visité un gymnase de Pont-Sainte-Marie (Aube) pour marquer le début de la reprise des activités sportives. Au total, 5,4 millions d’enfants seront éligibles à cette aide, qui sera disponible à la rentrée. « Cette reprise du sport est aussi le point de départ d’une nouvelle course de fond qui nous emmène jusqu’en 2024 », où l’objectif sera de « ramener le maximum de médailles », mais aussi de « vraiment faire de la France une nation sportive », a déclaré le président de la République. |
| CamemBERT-base «fine-tune»d w/ ML SUM K-Means labelized | Présent, 5,4 millions d’enfants seront éligibles à cette aide, qui sera disponible à la rentrée. L’exécutif table sur un taux d’utilisation de 50 % environ et compte renouveler cette aide en 2022. Après cette rencontre, Emmanuel Macron s’est rendu au stade municipal pour assister aux entraînements des jeunes du FC Pont Sainte Marie, et discuter avec eux. « Cette reprise, elle est extrêmement importante pour la santé de nos enfants », ainsi que l’alimentation, a-t-il aussi souligné. Via les diverses aides Covid, l’Etat a déjà déployé 3,5 milliards d’euros pour soutenir l’écosystème sportif, selon l’Elysée et 100 millions d’euros ont été budgétés pour ce nouveau dispositif. |
| CamemBERT-base «fine-tune»d w/ ML SUM TF-IDF labelized | Ce « Pass Sport », une aide de 50 euros par enfant, destiné aux familles qui perçoivent l’allocation de rentrée scolaire ou pour les enfants souffrant de handicap, aide à financer l’inscription dans un club affilié à une fédération – ou, dans les quartiers prioritaires de la ville, également à une association sportive. Emmanuel Macron a rappelé que la crise sanitaire avait été particulièrement « dure » pour les jeunes, qui ont dû faire des « sacrifices » dans leurs activités notamment sportives, mais il s’est félicité d’avoir fait le choix de les « préserver (…) en ouvrant au maximum les écoles ». « Cette reprise du sport est aussi le point de départ d’une nouvelle course de fond qui nous emmène jusqu’en 2024 », où l’objectif sera de « ramener le maximum de médailles », mais aussi de « vraiment faire de la France une nation sportive », a déclaré le président de la République. |
Analyse des résultats
Les résultats que j’ai obtenus, sont très satisfaisants. Le modèle CamemBERT fine-tuned avec le dataset ML-SUM labellisé par TF-IDF, parvient à capturer les idées importantes abordées dans un texte. J’ai également pu remarquer que les résumés générés par ce dernier sont plus complets que ceux générés par les méthodes de résumés extractives traditionnelles (TF-IDF, K-Means). En effet, ces méthodes traditionnelles ont tendance à introduire dans le résumé des termes anaphoriques pour faire référence plusieurs fois à des sujets qui ne sont pas évoqués dans le résumé. Le modèle K-Means commence le résumé par le terme anaphorique « cette aide » pour parler du « Pass Sport » alors que ce sujet de discussion est introduit plus tard dans le résumé. Ainsi, cela rend le résumé incompréhensible et incomplet car certains sujets prennent le dessus sur d’autres et les sujets importants sont oubliés.
12. Description de la Web App
L’application web ingètre le modèle CamemBERT et mBART'hez fine-tuned sur le dataset “MLSUM” pour générer des résumés de texte à partir d’article de journaux.
Pour développer cette application la stack technique est la suivante:
- Front-end :
Svelte.js - Back-end :
Flask - Méthodes de résumé de texte:
Camembert-base fine-tunedpour la génération extractive andmBART'hez fine-tunedpour la génération abstractive - Base de données :
MongoDB - Web Server :
NGINX
13. Identification des besoins
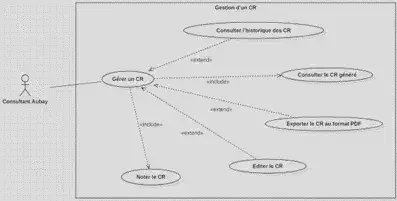
Gestion d’un CR
- Consulter les comptes-rendus de réunions préalablement générés
- Modifier les comptes-rendus pour permettre à l’utilisateur de corriger les éventuelles erreurs réalisées par les modèles. Dans une optique d’amélioration continue, cela contribuera également à constituer un dataset abstractif et extractif de meilleure qualité et plus volumineux.
- Exporter en PDF le compte-rendu.
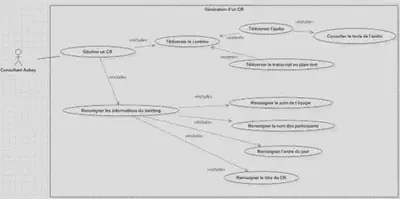
Générer un CR
- Générer un CR en téléversant le contenu audio ou bien la retranscription textuelle de la réunion
- Dans le cas d’un contenu audio, le résultat de la solution Speech To Text doit pouvoir être consulté
- Renseigner les informations associées à un CR (titre, nom du rédacteur, nom des participants et ordre du jour)
Les exigences techniques :
- Portable : Facilement transportable d’un environnement logiciel et/ou matériel à un autre. L’application pourra être déployée dans le cloud, en local, et ce, peu importe l’OS de la machine. Cela a pour but de réduire la difficulté qu’auront nos successeurs à reprendre notre travail.
- Modulaire : L’application est divisée en plusieurs composants indépendants qui interagissent entre eux afin de pouvoir remplacer facilement certains composants sans avoir à modifier le reste. Comme par exemple, modifier le modèle de Machine Learning sans pour autant devoir adapter l’interface ou la base de données.
- Adaptable & Maintenable : L’effort nécessaire à la modification du système suite à un changement des spécifications, à un ajout de nouvelles fonctionnalités ou une correction d’un bug doit être minimal. Cela se traduit par le respect des bonnes pratiques de développement et l’utilisation de langages et frameworks simples et couramment utilisés.
14. Architecture de la Web App
Afin de se conformer à la contrainte de modularité, j’ai fait le choix de diviser l’application en plusieurs parties en suivant le paradigme des architectures en micro-services. Aussi, j’ai séparé l’application en 4 parties différentes :
- Le frontend : c’est la partie “façade” de notre application qui correspond à l’interface graphique.
- Le backend : cela correspond au “cerveau” de la solution. Son rôle est de répondre aux différentes requêtes ou de les rediriger vers d’autres composants et d’interroger la solution de Speech To Text
- Le moteur d’IA : son rôle est d’encapsuler les deux modèles abstractifs et extractifs (
mBARThezetCamemBERT) et de répondre aux requêtes transmises par le backend. - La base de données : elle servira à stocker l’historique des opérations et d’autres données qui pourront être utilisées par la suite pour améliorer les modèles de résumé.
- Le serveur web : Le serveur permet de gérer les requêtes effectuées depuis l’application. Il sera en charge de gérer et répondre aux opérations que l’utilisateur exécutera depuis l’interface de l’application.
Ainsi, on obtient le schéma d’architecture simplifié suivant :

15. Choix techniques
Déploiement Afin de simplifier au maximum le déploiement, la gestion des dépendances et pour répondre au besoin de portabilité, chaque composant, développé indépendamment, est embarqué dans un conteneur Docker déployé avec Docker Compose. Docker permet de créer et de partager des applications conteneurisées ainsi que des micro-services. Un conteneur contient l’application et l’ensemble de ses dépendances. Cela facilite le lancement de la solution car il n’est pas nécessaire d’installer au préalable les dépendances du projet. Docker Compose permet de déployer une application distribuée dans plusieurs conteneurs à partir d’un simple fichier descripteur.
Frontend Pour le frontend, j’ai choisi de le réaliser en utilisant le framework Svelte.js. C’est un framework javascript très léger et complet qui a l’avantage de se charger très rapidement et d’utiliser peu de ressources. La seconde raison du choix de ce framework est le fait d’utiliser une autre solution de frontend, différente des classiques React, Angular ou Vue. Ainsi, je peux mesurer la viabilité de Svelte dans le cadre d’autres projets chez Aubay.
Backend Pour le backend, j’ai choisi « Flask », un framework python léger embarquant toutes les fonctionnalités nécessaires à notre projet. J’ avais besoin d’un framework python afin de pouvoir intégrer de manière plus simple le travail réalisé lors de la phase de POC.
Moteur d’IA Les données générées par les deux modèles de machine learning seront simplement mises à disposition et interrogées via une API REST développée en Python pour se connecter facilement aux librairies HuggingFace, Pytorch.
Base de données Afin d’enregistrer les opérations de l’utilisateur depuis l’application, j’ai choisi de construire une base de données avec « MongoDB ». Il s’agit d’une base de données NoSQL. Celle-ci orientée document est très simple d’utilisation et flexible. Cela permet, contrairement aux bases de données relationnelles SQL, de ne pas avoir besoin de passer beaucoup de temps à la concevoir (afin de se conformer à la deadline de la journée des stagiaires). De plus, les données que j’avais, sont très simples et peu nombreuses. J’aurais pu faire le choix de les stocker dans de simples fichiers textes mais MongoDB m’apporte de l’abstraction par rapport à la manière de stocker les informations et simplifie le travail. L’ensemble des informations d’un compte-rendu est stocké dans un fichier au format JSON.
{
"id": 0, // ID du CR
"title": "NLP_2021_CR_21_MAI", // Titre du CR
"projectGroup": "NLP", // Groupe projet associé à la réunion
"date": "21/05/2021", // Date de la réunion
"generatorName": "hmichel", // Nom du rédacteur
"attendees": ["attendee 1", "attendee 2", "attendee 3"], // Liste des paraticipants
"meetingProgram": "Présentation du workflow de l'app", // Ordre du jour
"transcript": "", // Transcriptions des voix vers en texte généré par la solution Speech To Text
"summary": {
"extractive": {
"raw": " Laurem solor sit amet ", // résumé brut généré par CamemBERT
"edited": " Laurem solor sit amet ", // résumé modifié par l’utilisateur sans aucun style CSS
"html": "<h1>Laurem solor sit amet</h1>", // résumé modifié par l’utilisateur comprenant le style CSS
"lastUpdate": "22/05/2021 12:05:22", // date et heure de la dernière modification
},
"abstractive": {
"raw": "", // résumé brut généré par mBART’hez
}
},
"status" : "done", // état de la génération du CR (processing/done)
},
Serveur web Afin de gérer les opérations exécutées depuis l’interface de l’application par l’utilisateur, j’ai fait le choix d’utiliser le serveur web NGINX. Il aura la charge de rediriger les requêtes vers la bonne brique logicielle de l’application pour y interroger les moteurs d’IA, la base de données ou bien la solution S2T en fonction des requêtes de l’utilisateur. L’avantage du serveur NGINX est qu’il fonctionne de manière asynchrone. Cela signifie que chaque requête peut être exécutée simultanément par le serveur sans bloquer les autres requêtes.
16. Workflow de l’application
Générer un CR à partir d’un audio
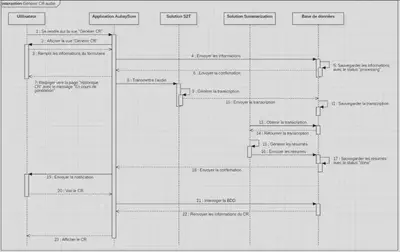
Modifier un CR
