Détection d’activité - Analyse d’une courbe de charge
Sommaire
- 1. Contexte
- 2. Motivations
- 3. Enjeux
- 4. Objectif
- 5. Formulation de la problématique
- 6. Technologie NILM (Non Intrusive Load Monitoring)
- 7. Architecture NILM
- 8. Les approches
- 9. Data
- 11. Labellisation
- 13. Metriques d’évaluation
- 14. Focus sur l’approche Non supervisée : Auto-Encodeur Convolutionnel pour la détection d’activité
- 14.1. Explication de l'approche
- 14.2. Pre-processing
- 14.2.1. Les étapes du pré-processing
- 14.2.2. Choix des paramètres
- 14.2.3. Construction du jeu d’entraînement et de test
- 14.2.4. Construction des séquences
- 14.3. Architecture du modèle
- 14.4. Entraînement du modèle
- 14.5. Evolution de la fonction de perte
- 14.6. Visualisation de la reconstruction de la courbe de charge base
- 14.7. Détection des anomalies
- 14.8. Post-Processing
- 14.9. Pipeline du modèle AEC
- 14.10. Evaluation du modèle sur la dataset The Rainforest Automation Energy Dataset
- 14.11. Evaluation du modèle sur la dataset UK-DALE
- 14.12. Futures améliorations possibles
- 14.13. Conclusion de l’approche non-supervisée : Auto-Encodeur Convolutionnel
1. Contexte
Le développement du réseau intelligent, en particulier le déploiement à grande échelle des compteurs intelligents, offre la possibilité de développer des applications d’analyse de données et d’aider les clients à accroître leur efficacité énergétique. Pour les particuliers, la mise en œuvre de compteur intelligent fournit un accès sécurisé aux données de consommation d’énergie de leurs propres maisons ou appartements, qui peuvent également être révélées à un tiers de confiance avec l’autorisation de l’utilisateur. Un système de gestion de l’énergie appliqué aux charges dans les bâtiments permet aux clients d’ajuster leur consommation d’énergie en fonction d’un niveau de confort attendu, des variations des prix de l’énergie et parfois des impacts environnementaux (par exemple les émissions d’équivalent CO2).
De telles stratégies de gestion de la demande nécessitent une évaluation précise de la quantité d’énergie qui peut être contrôlée. Par conséquent, l’identification de l’utilisation de chaque appareil est l’une des questions centrales de la gestion énergétique des bâtiments intelligents. Du point de vue des entreprises de services publics, la sensibilisation et la participation accrues des clients facilitent également le déploiement des compteurs intelligents et l’adoption de politiques telles que l’option de tarification en fonction de l’heure de consommation. Mais encore, l’identification de la charge peut également jouer un rôle important dans la prédiction future de l’utilisation d’appareils particuliers lorsque le processus de collecte des données historiques est rendu aussi peu intrusif que possible. Par conséquent, le développement d’outils d’analyse des données est la première étape vers une participation active des utilisateurs au développement futur des réseaux intelligents et des services associés. Sans aucun doute, l’analyse des données des compteurs intelligents offre de nouvelles possibilités aux consommateurs et aux entreprises de services publics pour la mise en place d’un réseau intelligent. Toutefois, à l’heure actuelle, les compteurs d’électricité intelligents ne fournissent que des données sur l’ensemble du logement. Cela signifie qu’il est nécessaire de séparer et d’identifier à partir de la charge totale la consommation électrique de chaque appareil.
Cette méthode s’appelle la désagrégation de l’énergie et requiert le développement d’algorithmes pour identifier la consommation électrique de chaque appareil électronique. Afin d’éviter cela les appareils d’une maison pourraient être surveillés directement, mais au prix de la fabrication et de l’installation de nombreux nouveaux appareils dans les maisons, de la gêne pour l’utilisateur et du fait que de nouveaux capteurs doivent être installés pour tout nouvel appareil.
2. Motivations
Le développement des compteurs intelligents tels que Linky, qui équipe désormais près de 35 mil- lions de foyers en France (chiffres Enedis 2021), ouvre les champs des possibilités dans le domaine de la détection d’activité. En effet, malgré le grand nombre de scénarios d’application potentiels, la détection de l’occupation des bâtiments reste un processus lourd, sujets aux erreurs et coûteux. L’occupation est généralement détectée à l’aide de dispositifs spécialisé tels que des capteurs infrarouges passifs, des interrupteurs magnétiques ou des caméras. Ces capteurs doivent être achetés, installés, calibrés, alimentés et entretenus. Cela pose un certain nombre de contraintes critiques, en particulier dans les environnements domestiques. Tout d’abord, le coût global de l’infrastructure de détection d’occupation doit rester faible. De plus, les capteurs fonctionnant sur batterie sont souvent utilisés pour éviter le déploiement des câbles d’alimentation. La disponibilité et la fiabilité des capteurs peuvent donc être affectées par des batteries épuisées en attendant d’être remplacées. En outre, dans un environnement domestique, l’un des résidents (souvent inexpérimenté sur le plan technique) joue le rôle d’administrateur du bâtiment qui installe et entretient le système. Les installations défectueuses et le manque de maintenance sont des conséquences fréquentes. L’ensemble de ces contraintes peut rendre des systèmes de détection d’occupation peu fiables et induire des comportements défectueux dans les systèmes domotiques qui en dépendent. Cela peut à son tour causer des désagréments aux résidents et entraver leur acceptation des systèmes.
Par ailleurs, au-delà des contraintes posées par ces types de dispositifs (lourde maintenance, coût élevé, installation défectueuse,…) au sein d’un environnement domestique, il s’avère que ces derniers sont des solutions intrusives pas forcément acceptées par le public. Cela constitue alors la principale motivation de l’introduction de nouvelles technologies non intrusives à partir des courbes de charge de consommation électrique. Les méthodes non intrusives offrent une alternative intéressante, avec un coût d’installation très réduit. Les compteurs intelligents sont l’une des unités fondamentales des réseaux intelligents, car de nombreuses autres applications dépendent de la disponibilité d’informations à granularité fine sur la consommation et la production d’énergie.
Ces dernières années une attention particulière a été accordée aux recherches visant à déduire l’activité des ménages par l’analyse de la consommation de leurs appareils. Ces systèmes sont connus sous le nom de la surveillance de la charge des appareils non intrusifs (NILM).
3. Enjeux
Le sujet de la détection d’activité est un sujet porté par de nombreux acteurs économiques et qui peut être source de nombreux services aux usagers.
Notamment :
- Sécurisation des logements notamment les logements secondaires ou les logements mis en location temporaire
- Prolonger l’autonomie des seniors en leur permettant un maintient à domicile, en alertant les proches ou le personnel médical en cas d’absence anormal d’activité
- Détection de l’heure du retour de l’école des enfants
Les solutions actuelles sont des solutions intrusives, pas forcément acceptées ni simples à installer: par exemple via l’installation de différent type de capteurs qui vont monitorer la présence des habitants etc…
La problématique NILM a longtemps été étudiée par des chercheurs. La plupart des approches sont basées sur le traitement du signal à un taux d’échantillonnage élevé (1 Hz typiquement) pour évaluer la signature de la charge de l’appareil et ensuite utiliser des techniques de reconnaissance des formes pour l’identification à partir de classifieurs préalablement formés. Cela nécessite l’installation d’un capteur pour chaque appareil dans la maison et est donc naturellement limité par cet important système de surveillance de la charge. D’un point de vue social, un obstacle majeur dans la recherche de NILM est le respect de la vie privée de l’utilisateur, car l’utilisation de l’appareil peut être liée au comportement de l’utilisateur. Par exemple, l’heure à laquelle les lumières sont éteintes peut être considérée comme l’heure de sommeil de l’habitant. Enfin, il reste à développer une méthode non intrusive qui fonctionne pour tous les appareils de la maison.
Tout l’enjeu de ce projet est donc travailler sur les technologies non intrusives de détection d’activité à partir des courbes de charge de consommation électrique. Plus concrètement, il s’agira de construire des algorithmes de Machine Learning qui vont permettre de faire une classification binaire prédisant l’activité du logement, avec la contrainte de pouvoir s’adapter à différent types de logements pour lesquels on n’a pas de données labellisées (unsupervised learning).

4. Objectif
Travailler sur les technologies non-intrusives de détection d’activité à partir des courbes de charge de consommation électrique.
5. Formulation de la problématique
Typiquement, on peut distinguer trois catégories de consommation:
Consommation de tous les appareils en veille
Consommation des équipements qui se déclenchent et s’éteignent seuls (type frigo, ballon d’eau chaude… etc
Consommation des équipements déclenchés par l’utilisateur
Seule cette dernière catégorie d’équipement permet de détecter une réelle activité dans le logement.
L’objectif est donc de concevoir des algorithmes de Machine Learning qui vont permettre de faire une classification binaire prédisant l’activité du logement, avec la contrainte de pouvoir s’adapter à différent types de logements pour lesquels on n’a pas de données labelisées (unsupervised learning)
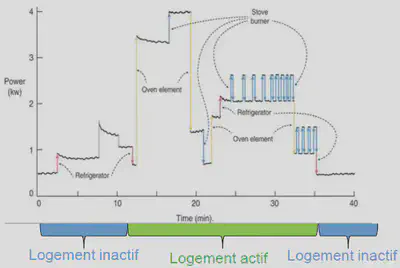
6. Technologie NILM (Non Intrusive Load Monitoring)
Le champ de recherche dédiée à la désagrégation de l’énergie porte le nom de « Non Intrusive Load Monitoring » (NILM). Ces technologies convertissent une série chronologique de données de consommation d’énergie (courbe de charge) en une courbe de charge par appareil. En décomposant un ensemble de relevés de consommation d’énergie globale en ses parties constitutives consommées par des appareils individuels, les algorithmes de désagrégation de l’énergie permettent à un client résidentiel d’obtenir des informations détaillées sur la consommation d’énergie de tous les appareils de la propriété et donc de mieux comprendre la facture d’électricité. Un système de désagrégation de l’énergie est composé à la fois d’algorithmes de désagrégation et du matériel nécessaire à la collecte des données de consommations énergétiques comme un compteur intelligent. Bien que certains travaux existants proposent le déploiement d’équipements spécialisés et parfois sophistiqués, la réduction des niveaux d’invasivité de ces systèmes est considérée comme l’étape cruciale vers des solutions pratiques de NILM.
Les méthodes de séparation des charges peuvent être classées en fonction du degré d’intrusion du processus de formation et de la nature de l’algorithme de classification (basé sur des événements ou non). L’algorithme basé sur les événements tente de détecter les transitions marche/arrêt, tandis que les méthodes non basées sur les événements tentent de détecter si un appareil est allumé pendant toute la durée de l’échantillonnage.
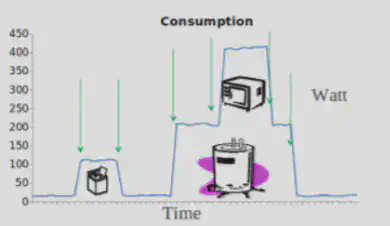
L’idée de la reconnaissance d’activité a été étudiée en premier lieu dans le domaine de la santé pour détecter les situations d’urgence en surveillant les activités et les mouvements quotidiens des patients. Mais ces techniques de reconnaissance reposent souvent sur des capteurs supplémentaires et sont donc intrusives et peuvent être coûteuses. Le NILM comprend un ensemble de techniques pour la surveillance non intrusive de la charge. Son but est de déterminer les changements de tension et de courant entrant dans une maison et de déduire quels appareils sont utilisés dans la maison.
La détection d’activité s’appuie sur la détection d’événements, par exemple, l’allumage et l’arrêt d’appareils et le changement de mode ou d’état de fonctionnement des appareils. Cela suppose alors que la variation de la charge est causée par un seul appareil or cela n’est pas toujours le cas en pratique.
Du point de vue des sciences du comportement, la compréhension du calendrier des activités du consommateur (activity modeling) facilite l’étude des pratiques sociales des consommateurs en termes d’ordonnancement et de chevauchement dans le temps. Du point de vue de l’ingénierie, la compréhension du calendrier des activités peut contribuer au déplacement de la charge et à la gestion de la demande puis concevoir des programmes de gestion de la demande appropriés.
D’un point de vue de la recherche, les méthodologies employées pour résoudre des problématiques NILM englobent plusieurs domaines. Une majorité des premières recherches se sont concentrées sur ce problème du point de vue du traitement du signal. L’accent a été mis sur l’identification des différentes signatures d’appareils qui distinguent un appareil d’un autre en l’analysant à l’aide d’outils mathématiques.
Des recherches ultérieures ont également considéré le problème comme une tâche de séparation aveugle des sources et ont proposé des techniques pertinentes dans cette direction [Kolter 2010 ]. Ensuite, les problématiques NILM sont considérés comme un problème de classification temporelle pour l’identification des appareils électroménagers basée sur un processus d’apprentissage multi-classes utilisant un fenêtrage temporel où la seule entrée est le relevé d’énergie horodaté du compteur électrique.
Plus récemment, l’avènement du Deep Learning ouvre les champs des possibilités pour la résolution des problématiques NILM. Ces techniques et notamment les réseaux de neurones LSTM sont utilisés pour la détection d’activité à partir de la courbe de charge.
7. Architecture NILM
L’architecture du processus d’identification de la courbe de charge de chaque appareil électronique à partir de la courbe de charge totale du domicile se présente comme suit :
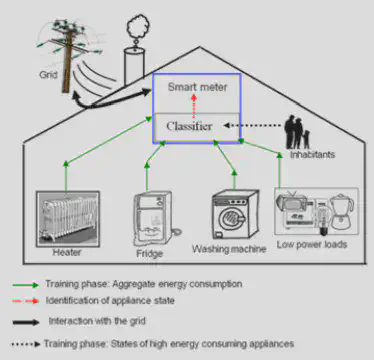
Dans une architecture NILM, les interactions entre les habitants, les consommations électriques de chaque appareil et le réseau électriques sont centralisée en un point de convergence. Ce point de convergence est la compteur intelligent. Un classifieur est directement intégré dans le compteur intelligent. Ce dernier est entraîné avec les données collectées pour chaque appareil par le compteur intelligent afin de prédire s’il y a activité ou non au sein d’un foyer à partir de la courbe de charge agrégée.
8. Les approches
- Approche supervisée :
Time2VecetBoosting Classifier - Approche non supervisée :
Auto-Encodeur Convolutionnel
9. Data
- Dataset Open Source de courbe de charge labellisées
10.1. RAE: The Rainforest Automation Energy Dataset
Les données utilisées dans un premier temps sont celles provenant du papier RAE: The Rainforest Automation Energy Dataset (Makonin & Stephen, 2017). Le jeu de données comprend des relevés de puissances échantillonnés à 1 Hz sur deux maisons à Vancouver sur une durée de respectivement 72 jours (découpée en deux périodes de 9 puis 53 jours) et 59 jours. La première maison est équipées de 24 sous-compteurs (un par disjoncteur) et est habitée par 3 occupants au niveau supérieur et 1 occupant au niveau inférieur.
La deuxième maison est équipée de 21 sous-compteurs et est occupée par 3 occupants. Chaque sous- compteur a été étiqueté pour pouvoir facilement identifier la source de consommation. Du fait que les deux maisons soient situées au Canada, certains gros équipements sont répartis sur deux sous-compteurs.
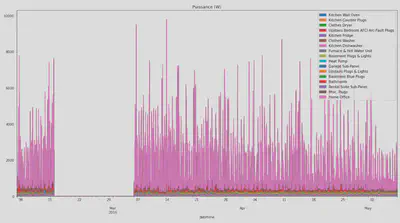
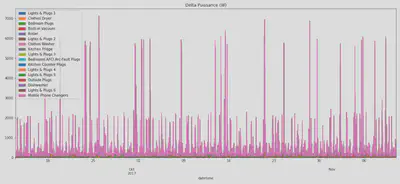
Afin de n’avoir qu’une mesure de puissance par équipement les sous-compteurs ont été regroupés dans la suite de l’étude.
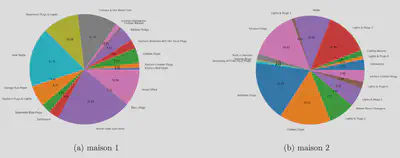
On peut observer le graphique circulaire de la répartition du pourcentage des puissances sur la puissance totale consommées dans les deux maison. Dans la maison 2 nous avons retiré le compteur étiqueté ’House Sub-Panel’ qui correspond à la courbe de puissance agrégée sur tous les sous-compteurs. On constate que dans la maison 1 la plus grosse consommation provient des sous-compteurs ’Rental Suite Sub-Panel’. Il s’agit d’un compteur pour le niveau inférieur complet (occupé par une personne), c’est-à-dire une courbe de puissance déjà agrégée.
10.2. UK-DALE
Notre jeu de données présente deux maisons, ce qui nous a permis de tester nos approches et d’essayer de voir si nos modèlent se généralisent bien d’une maison à une autre. Pour aller plus loin il serait cependant intéressant d’avoir un jeu de données indépendant pour tester nos modèles sur d’autres scénarios.
Pour cela nous avons utilisé le je de données provenant du papier The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes (Jack Kelly, 2015). Ce jeu de données est très riche puisqu’il comprend des relevés de puissances échantillonnés à 6 Hz sur cinq maisons au Royaume-Unis sur des durées allant de 39 à 234 jours. Chaque maison est découpée en plusieurs sous-compteurs qui correspondent tous à un appareil électrique. Les appareils électriques ne sont pas tous relevés mais chaque maison dispose du relevé total agrégé sur tout le logement. Nous avons fait le choix de labelliser la maison 2 de ce jeu de données car c’est la maison qui présente des relevés de mesure sur la plus grande période de temps (234 jours au total, 142 jours après réconciliation de toutes les mesures et nettoyage) et avec un bon niveau de détail au niveau des appareils électriques dont la puissance est mesurée.
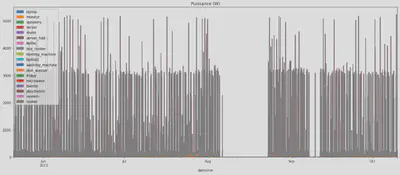
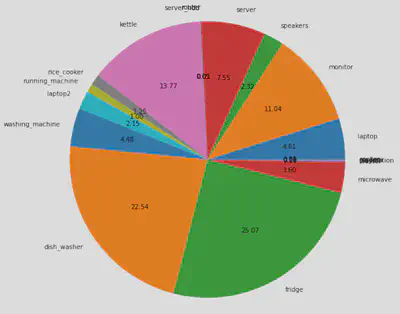
On peut également observer le graphique circulaire de la répartition du pourcentage des puissances sur la puissance totale consommées ce logement.
11. Labellisation
Le Data Labelling ou étiquetage des données est une étape indispensable du Machine Learning. Pour entraîner une IA à partir de données, il est impératif d’étiqueter ces données au préalable. Le Machine Learning permet à nos ordinateurs d’apprendre de manière autonome, en s’entraînant à partir des données. Toutefois, pour que l’apprentissage de nos modèles puisse commencer, nous devons intervenir.
Avant de nourrir le modèle avec des données, il est indispensable de les préparer. À l’aide de divers outils, nous allons assigner des étiquettes aux données. C’est ce qui permettra ensuite à notre modèle d’apprendre à reconnaître s’il y a activité ou non. Dans notre cas afin d’entraîner convenablement nos modèles de Machine Learning, nous allons dans un premier temps labelliser manuellement chaque courbe de charge de chaque appareils. Pour identifier s’il y a activité nous ferons varier trois paramètres basés sur des règles métier : un seuil, un lissage puis un second seuil.
La prise de décision algorithmique est sujette à un biais axé sur la personne qui analyses les données ainsi qu’à un biais sur les données. Dans notre situation les étapes d’entraînement et d’évaluation des modèles reposent sur des données étiquetées manuellement et peuvent contenir un biais, ce qui entraînerait des omissions dans un modèle prédictif, bien que l’algorithme d’apprentissage automatique soit le plus optimal. Les données étiquetées utilisées pour former un algorithme d’apprentissage automatique spécifique doivent être un échantillon statistiquement représentatif et ou le moins biaisé possible afin d’obtenir les meilleurs résultats possible
12.1. Méthodologie utilisée
Afin d’étiqueter nos jeux de données, chacune des courbes de charge correspondantes à un souscompteur ont été étudiées. Les sous-compteurs sont labellisés, certains sont liés à des appareils qui ne correspondent pas à de l’activité (pompe à chaleur, frigo, etc.). Ces courbes ont été ignorées. Parmi les autres courbes, celles présentant un signal trop faible (environ moins que 300W en charge maximum) ont également été ignorées car ces signaux seront noyés dans la courbe agrégée et risquent de ne pas pouvoir être détectés de manière fiable. Enfin les courbes présentant beaucoup de bruit ont également été ignorées lors de cette analyse car elles ne permettent pas de clairement identifier de phases d’activité vs non activité. Les courbes restantes ont été analysée et traitées en trois étapes décrites ci-dessous afin de rajouter un label activité vs non activité.
Etape 1 : Dans cette première étapes nous créons un premier seuil en sommant la puissance moyenne à laquelle nous ajoutons l’écart-type multiplié par un coefficient que nous faisons varier pour chaque courbe de charge afin d’obtenir les meilleurs résultats possibles. Si la courbe de puissance dépasse ce seuil on considère qu’il y a activité.
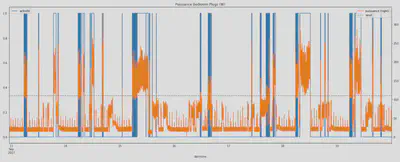
Etape 2 : Dans l’objectif de mieux visualiser la courge de charge de l’appareil à analyser, et afin d’éviter les alternances activité / non activité à trop haute fréquence nous appliquons un lissage en faisant une moyenne glissante. La durée de la fenêtre sur laquelle la moyenne glissante est appliquée a été définie au cas par cas afin de coller au mieux aux périodes d’activité / non activité observées. Dans l’exemple ci-dessous le lissage fait d’avantage ressortir les variations de consommation de puissance de l’appareil.
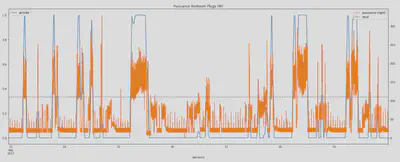
Etape 3 : Une fois la courbe lissée nous appliquons un deuxième seuil. Nous considérons qu’il y a activité si la courbe d’activité lissée dépasse un certain seuil (le seuil égal à zéro dans cet exemple). Cela permet d’avoir un label 1 ou 0 qui correspond au label final pour ce sous-compteur : activité ou pas. Une fois ce traitement fait sur chacune des courbes de charge retenues pour une maison données, les courbes d’activité par sous-compteur ont été agrégées afin d’obtenir la courbe finale de l’activité en fonction du temps pour les deux maisons de notre jeu de données.
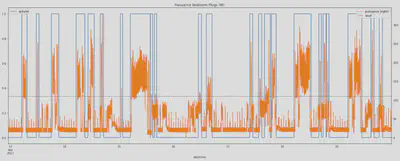
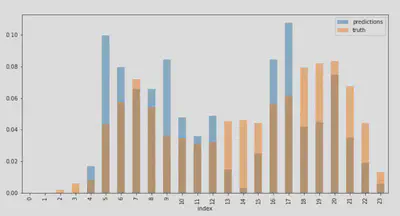
On peut observer les histogrammes des labels activité par heure de la journée pour chaque courbe de charge désagrégée. Les appareil retenus pour le label activité final sont affichés en bleu, les appareils qui n’ont pas été pris en compte sont en gris.
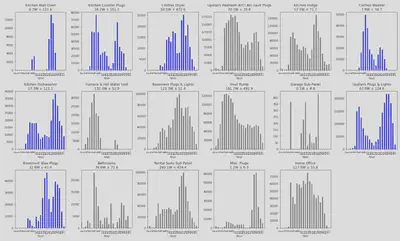
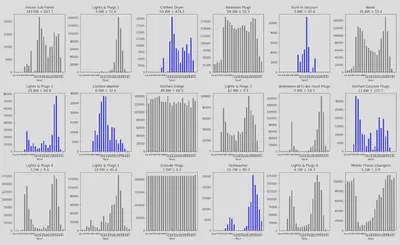
12.2. Discussion des résultats
Encore une fois, une telle méthode n’est pas idéale car on ne connaît pas la courbe d’activité réelle (“ground truth”), mais il s’agit de la meilleur approximation possible au vue des données disponibles. Les jeux de données correspondants à des courbes de charge désagrégées dans des logement sont rares, et il n’existe pas de jeux de données avec des labels correspondants à de l’activité dans un logement à notre connaissance. Nous allons utiliser ces labels pour nos tâches de classification, tout en restant prudents lors de l’interprétation des résultats.
Une façon de pouvoir juger de la qualité des résultats obtenus est d’observer les histogrammes de la courbe activité par tranches d’une heure (de 0 à 23) pour chacune des maisons.
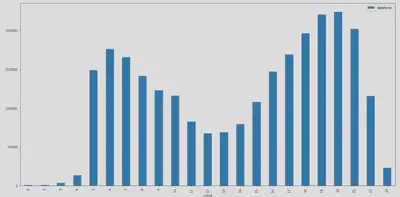
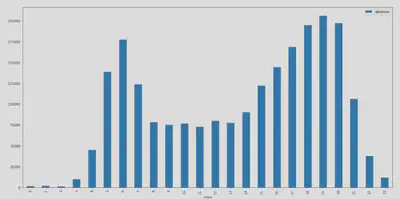
Sur les deux histogrammes on observe deux pics d’activité : un vers 6h du matin et un autre vers 19h / 20h. Ces pics peuvent correspondre respectivement aux heures de levée et de retour du travail le soir. On observe qu’on ne labellise pas de périodes d’activité durant la nuit (de 23h à environ 4h du matin), ce qui semble cohérent avec ce à quoi on pourrait s’attendre pour l’activité d’un foyer.
13. Metriques d’évaluation
Comme expliqué dans les parties précédentes la finalité du projet est de pouvoir détecter une activité à partir de la mesure instantanée de la puissance électrique d’un logement provenant d’un compteur intelligent Linky. Ceci peut être utile dans le cadre de nombreux services aux usagers.
Le but est donc de pouvoir faire une classification binaire (activité ou pas) à partir de la mesure de la consommation de puissance électrique d’un logement. Cette classification devra être la plus précise possible tout en s’adaptant à tout type de logement. À la vue des applications finales il sera important de ne pas avoir un taux de faux positifs trop important, c’est-à-dire éviter de prédire de l’activité alors qu’il n’y en n’a pas. Surtout dans le cadre de la détection d’activité pour un senior, il sera plus prudent d’accepter un taux de faux négatifs élevé (ne pas prédire de l’activité alors qu’il y en a) ce qui aurait comme effet potentiel de déclencher une fausse alerte, plutôt que de ne pas déclencher d’alerte lorsque cela aurait été nécessaire. Cette philosophie sera importante pour le choix de la métrique de mesure de performance de nos algorithmes.
13.1. $F_\beta$ score
Ces contraintes nous permettent déjà d’orienter nos choix pour la métrique d’évaluation de nos classifieurs. En plus de l’accuracy, il sera important de calculer et maîtriser le taux de rappels. Une métrique intéressante est le score $F_\beta$ définie par : $$ F_\beta = (1+\beta^2) \frac{\text{précision} \cdot \text{rappel}}{\beta^2 \cdot \text{précision} + \text{rappel}} $$
On peut également écrire ce score sous la forme suivante : $$ F_\beta = \frac{(1+\beta^2) \cdot \text{vrai positif}}{(1+\beta^2) \cdot \text{vrai positif} + \beta^2 \cdot \text{faux négatif} + \text{faux positifs}} $$
En prenant $\beta = 0,5$ on peut ainsi donner moins de poids aux faux négatifs et donc plus de poids aux faux positifs (ceux-ci auront plus d’impact sur le score final).
Dans la littérature pour des classifications binaires de ce type à partir de courbes de charge, on observe souvent un score accuracy autour des 80%. Il sera donc intéressant de garder cet ordre de grandeur en tête lors de nos tests afin de voir si nous parvenons à reproduire ces résultats, voire à aller plus loin. Un challenge auquel on peut s’attendre sera de pouvoir obtenir des modèles suffisamment généralistes pour pouvoir être appliqué sur différents logements. Il sera notamment intéressant de pouvoir appliquer un modèle entraîné à partir des données d’un logement donné sur un autre logement tout en conservant un score acceptable.
13.2. mAP score, mAR score
Les premières approches pour évaluation la qualité des prédictions d’un modèle reposaient sur la comparaison ligne à ligne de la classification de l’activité. Pour chaque instant, c’est à dire chaque seconde du dataframe, on se trouve alors dans l’un des 4 cas suivants:
- Activité réelle et prédiction d’activité : vrai positif
- Activité réelle et prédiction d’inactivité : faux négatif
- Inactivité réelle et prédiction d’inactivité : vrai négatif
- Inactivité réelle et prédiction d’activité : faux négatif
Et à partir de ces quatre cas on peut dériver les métriques de performance usuelles : précision, recall ; et afficher la matrice de confusion. Cette approche est un bon point de départ mais l’on peut se poser des questions sur l’adéquation entre cette métrique et la tâche qui nous incombe :
- De changements erronés bref et à haute fréquence ne sont pas vraiment pénalisé par cette approche. Théoriquement il serait possible d’indiquer de l’activité au moins une seconde à chaque minute et tout de même avoir de très bonne performances.
- Un déphasage léger et constant est sanctionné, alors que ce n’est pas un problème en réalité.
- Enfin, la vision suggérée par cette première approche est que les échantillons peuvent être traités de manière indépendante, ce qui ne fait pas forcément sens si on considère le temps comme une succession d’instants.
Nous avons donc défini une nouvelle métrique de performance pour essayer de mieux refléter l’esprit du cas d’usage : peut importe qu’il y ait un peu de déphasage, l’important est que les périodes d’activité et d’inactivité s’alignent au maximum. Cette métrique est inspirée des mesures de performance en computer vision pour les tâches d’object detection et repose sur le calcul d’IoU (Intersection over Union)
Le premier changement est de passer d’une vision de Timestamps indépendants à une vision considérant les périodes, ce qui implique de retravailler les données pour obtenir des périodes d’activité réelle et prédite.

On se donne alors deux métriques de performance :
- mean Average Precision -
mAP: pour chaque période d’activité prédite, quelle est le taux d’adéquation (y a-t-il une période d’activité réelle correspondante ou non) - mean Average Recall -
mAR: pour chaque période d’activité réelle, quelle est le taux de d’adéquation (y a-t-il une période d’activité prédite correspondante ou non)
A noter que d’après les exigences de notre problème, nous devons en priorité satisfaire un niveau élevé sur le mAP.
L’idée de la métrique de performance IoU est de calculer pour chaque période prédite(cas du mAP) l’adéquation avec la/les périodes réelles les plus proches en terme d’IoU et de décider selon un seuil si la période prédite est valide ou non. On fera ensuite varier le seuil, et on procèdera de même pour chaque période réelle ensuite(cas du mAR).
13.3. Alogrithme 1 | Principe d’évaluation : $mAP$
Algorithme 1 | Principe d'évaluation : $mAP$
return: scores du $mAP$ pour différents seuils séparés par $\tau$
$t \gets 0$
while $N \neq 1$ do
$t \gets t + \tau$
for chaque période d’activité prédite do
Calculer la meilleure $IoU$ possible vis à vis des périodes d’activité réelle
Statuer sur la validité de la période prédite au seuil $T$
end for
end while
$mAP$ $$ m A P(\tau)=\frac{\text { valid }_{\text {pred }}(\tau)}{\text { total }_{\text {pred }}} $$
$mAR$ $$ m A R(\tau)=\frac{\text { valid }_{\text {true }}(\tau)}{\text { total }_{\text {true }}} $$
13.4. Inter over Union Threshold - IoU
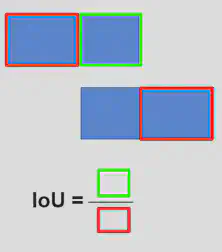
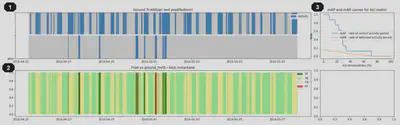
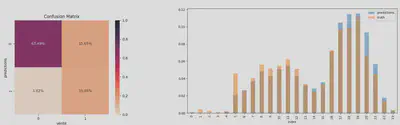
Finalement, on obtient le type de panel d’évaluation présenté sur la figure 6 avec :
- Activité réelle (haut) vs activité prédite (bas)
- Superposition activité réelle/prédite et association TP / FP / TN / FN = matrice de confusion
- $mAR$ et $mAP$ pour différents seuils de la métrique de performance IoU Cette méthode d’évaluation est utilisable de manière autonome, et ne dépend pas du modèle considéré
Une difficulté liée au jeu de données de départ est que ce dernier ne possède pas d’étiquettes pour l’activité. Pour la suite de ce projet nous allons devoir soit reposer sur des algorithmes non supervisés, ce qui serait limitant en termes de résultats et qui n’est pas forcément traité dans la littérature sur le sujet, soit appliquer un premier algorithme de d’étiquetage, afin de créer des étiquettes pour pouvoir ensuite appliquer des algorithmes d’apprentissage supervisé. Pour générer des étiquettes, nous pouvons utiliser des règles métier, si la puissance de certains équipements dépasse un certain seuil par exemple nous pouvons estimer qu’il y a de l’activité. Il conviendra d’appliquer une approche conservatrice à ce stade également pour éviter d’étiqueter de l’activité alors qu’il n’y en n’a pas. À la différence des données finales où nous ne disposerons que de la courbe de charge totale (agrégée), ce jeu de données présente l’avantage d’avoir plusieurs courbes de charges (une par disjoncteur).
Pour obtenir le score final permettant d’évaluer la qualité des prédictions générées pour le modèle, nous avons fait le choix de calculer l’aire sous les courbes $mAP$ et $mAR$. Plus l’aire sous chacune des courbes est élevée meilleures seront les prédictions générées par le modèle. Pour ce faire, nous avons appliqué les sommes de Riemann puis sommer l’aire de la courbe $mAP$ et $mAR$ comme suit:
- 1 : $AUC_{mAP} + AUC_{mAR}$
- 2 : $AUC_{mAP} \times \alpha + AUC_{mAR} \times \alpha$ avec $\alpha$ un poids attribué au valeur $mAP$ et $mAR$
14. Focus sur l’approche Non supervisée : Auto-Encodeur Convolutionnel pour la détection d’activité
L’objectif recherché ici est de modéliser le comportement normale des activités quotidiennes d’un foyer. Autrement dit, l’idée principale qui se cache derrière la détection d’activité est d’utiliser les caractéristiques de la consommation d’électricité qui se produisent uniquement dans les ménages d’une personne. Pour détecter une activité anormale, la consommation électrique de base (i.e courbe de charge de base) doit être identifiée préalablement. La charge de base fait référence à une charge générée par des sources de consommations d’électricité constantes comme un réfrigérateur, un congélateur, un appareil électronique branché en veille,…). En extrayant la charge de base de la consommation totale d’électricité, nous pouvons identifier l’activation de l’appareil par une seule personne.
Ainsi, l’encodeur se charge de trouver une représentation fidèle de la consommation normale des activités quotidienne d’une maison en y apprenant la courbe de consommation électrique de base c’est à dire la courbe de charge pour laquelle aucune activité est détectée (courbe de charge nocturne par exemple). Quant au décodeur, son objectif sera de reconstruire la courbe de consommation électrique normale apprise par l’encodeur.
Plus précisément, la courbe de charge de consommation normale (ou courbe de charge de base) correspond tout simplement, à la consommation totale des appareils électroniques en veilles à savoir les appareils qui sont continuellement en fonctionnement ou bien qui s’activent automatiquement à certaines période de la journée sans aucune intervention humaine, comme c’est le cas pour des appareils tel que le frigo, le réfrigérateur et les appareils de chauffage tel que la pompe à chaleur et la climatisation qui s’allument automatiquement par exemple pour maintenir une température souhaité à l’intérieur d’une maison.
14.1. Explication de l’approche
Pour obtenir cette courbe de charge de consommation normale synonyme d’inactivité dans un foyer, deux possibilités s’offrent à nous :
- Stratégie n°1 : Se référer à la courbe de charge nocturne de manière à capturer la consommation électrique totale de tous les appareils en veille ou en fonctionnement constant.
- Stratégie n°2 : Sélectionner individuellement la consommation électrique de chacun des appareils qui lorsqu’ils sont en fonctionnement nous permettent d’en déduire une activité au sein de la maison. Ces appareils en question pourraient être par exemple, les réfrigérateur, le frigo, la pompe à chaleur autrement dit tous les appareils qui sont constamment sous tension et ce même si le logement est inocuppé.
La stratégie n°1 est bien plus généralisable car on ne connaît jamais à l’avance le nombre et le type d’appareils électriques utilisés au sein d’une maison. Toutefois, cela requiert de connaître les périodes creuses qui généralement font référence à la nuit (i.e de 23h à 6h)
Les grandes étapes que nous avons suivi pour la détection des anomalies dans les données en utilisant un Auto-Encodeur Convolutionnel sont les suivantes :
- Pre-processing : Découper la courbe de charge de base qui se présente sous la forme d’une série temporelle en plusieurs séquences.
- Entraînement d’un Auto-Encodeur Convolutionnel sur la courbe de charge de base. Ainsi, nous supposons qu’il n’y a pas d’activité et donc que les données sont considérées comme étant “normales”.
- Reconstruction de la courbe de charge de base : Utilisation l’Auto-Encodeur Convolutionnel pour reconstruire la courbe de charge de base.
- Calcul de l’erreur de reconstruction : L’erreur sur les données correspond à la distance maximale entre la courbe de charge fournit à entrée du modèle et la courbe de charge reconstruite par le modèle (i.e perte maxitmale MSE).
- Prédiction des activités : Si l’erreur de reconstruction pour les données de test est supérieure au seuil (threshold), nous étiquetons les points de données de la séquence en question comme une anomalie.
- Post-Processing : Pour affiner nos prédictions, étant donné que plusieurs séquences utilisées pour l’entraînement du modèle peuvent se chevaucher, un point de données peut se trouver à la fois dans une séquence prédite comme étant une anomalie et inversement. Pour résoudre ce problème nous appliquons un vote majoritaire. Cela signifie que si le point de données en question se retrouve par exemple 3 fois dans une séquence prédite comme une anomalie et 2 fois dans une séquence prédite comme normale alors ce point de données sera annoté comme une anomalie
14.2. Pre-processing
Le Pre-processing est une étape crucial dans notre approche sans quoi l’entraînement de l’AutoEncodeur Convolutionnel ne sera pas possible. Comme évoqué précédemment, le rôle de la phase de pre-processing est de découper la courbe de charge agrégé en plusieurs séquences. Toutefois avant de se lancer dans la construction des séquences, des étapes transformations préalables doivent être opérées sur les données.
14.2.1 Les étapes du pré-processing
Plus précisément, les étapes de pré-processing sont les suivantes :
- Lecture et re-échantillonage de la courbe de charge
- Séparation des données de consommation électrique en un jeu de données d’entraînement et jeux de données de test. Les dimensions du jeu de test est de choisi par l’utilisateur
- Normalisation des données d’entraînement et de test
- A partir du jeu de données d’entraînement, construction d’un jeu de données qui correspond à la courbe de charge de consommation de base. Pour cela, l’utilisateur définis la plage horaire des heures creuses. Bien souvent cette plage horaire correspond à la nuit.
- Création de séquences d’entraînement et de test. La longueur des séquences et le taux de chevauchement entre les séquences sont définis par l’utilisateur.
14.2.2. Choix des paramètres
En amont de la phase de pré-processing, nous avons décidé de laisser à l’utilisateur le choix de déterminer certains paramètres qui régissent la création des séquences d’entraînement à partir de la courbe de charge de base. Cela permet alors au modèle de gagner en flexibilité mais aussi de pouvoir s’adapter au comportement de la consommation électrique quotidienne d’un foyer. De cette façon, le modèle bénéficie d’un pouvoir de généralisation plus élevé puisque ce dernier adapte la construction de la courbe de charge de base à chacun des foyer dont il doit détecter l’activité. Or il s’avère bien souvent qu’en fonction de la composition du foyer, les routines et habitude quotidienne peuvent varier très fortement. Par exemple, une personne qui pratique les postes de nuit n’a pas la même routine qu’une personne exerçant une fonction en tant que cadre. Grâce à la flexibilité offerte par le modèle durant la phase de pre-processing, ces spécificités peuvent être prisent en compte.
Choix des paramètres d’entrée Ainsi, l’utilisateur doit choisir les valeurs des paramètres suivants :
timeStep: durée d’une étape dans l’ensemble de données de re-échantillonnage (initialement 1 seconde)durationTime: durée d’une séquenceoverlapPeriodPercent: taux de chevauchement des données entre chaque séquencetimeframes: plage horaire des heures creusesrandomdays: pour sélectionner des jours aléatoires (19h->18h59 du landemain)
Tout l’intérêt du preprocessing est de s’adapter au mieux à la routine quotidienne d’une famille pour pouvoir bien extraire la courbe de charge de base (courbe de charge nocturne)
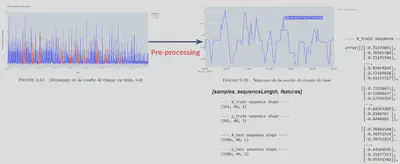
Ensuite le preprocessing construit les différentes séquences qui se chevauchent. Par exemple, la sortie du preprocessing est un tableau D3 $[samples, sequence_length, features]$
14.2.3. Construction du jeu d’entraînement et de test
Pour construire le jeu de test, on tire à aléatoirement 20% des jours qui composent notre dataset. Les jours restant forment le jeu d’entraînement.
14.2.4. Construction des séquences
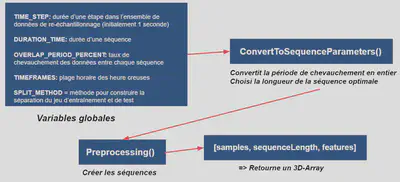
Sur la base des valeurs entrées par l’utilisateur, nous avons définis une fonction $convertToSequenceParameters()$ qui prend en argument l’ensemble des paramètres expliqués précédemment afin de déterminer la longueur de la séquence optimale ainsi que la période de chevauchement des données entre chacune des séquences.
On comprend bien que la longueur de la séquence ainsi que la période de chevauchement des données sont cruciaux afin de pouvoir capturer l’ensemble des fluctuations rapides ou lentes de la courbe de charge de base. En effet, une activité au sein d’une maison peut aussi bien être de très courte durée (quelque minutes) que d’une durée plus longue s’étalant sur plusieurs heures. La phase de pré-processing retourne alors un tableau en 3 dimensions $[samples, sequenceLength, features]$.
Il s’agit de la structure de données requis pour pouvoir être ingéré par le réseau convolutionnel de l’autoencodeur.
samples: Contient l’ensemble des échantillons de la courbe de charge qui ont été découpé en séquence temporellesequenceLength: Longueur de la séquence temporellefeatures: Contient la valeur de puissance de consommation électrique à un instant T
A noter que par exemple, si nous souhaitons que notre réseau ait une mémoire de 10 jours alors, nous définissons $sequenceLength = 10$.
En conclusion, tout l’intérêt du preprocessing est de s’adapter au mieux à la routine quotidienne d’une famille et ce quelque soit sa composition. C’est pour cela que nous avons souhaité rendre la phase de preprocessing la plus flexible et paramétrable possible en laissant le choix à l’utilisateur de définir un certains nombre de paramètres qui sont déterminantes pour la construction des séquences de la courbe de charge de base et qui doit refléter le plus fidèlement possible à la fois la configuration du foyer et la routine quotidienne de la famille.
14.3. Architecture du modèle
Pour détecter les activités au sein d’une maison, nous avons décidé d’utiliser un auto-codeur convolutionnel. Le modèle prend en entrée une séquence de la dimension suivante $(batchSize, sequenceLength, numFeature)$ retourne une sortie de la même forme. Dans notre cas, $numFeatures$ sera toujours égale à 1 car nous avons besoin d’une seule features à savoir la puissance consommée par le foyer à l’instant T. Enfin, $sequenceLength$ prend la valeur qui a été définit lors de la phase de pré-processing.
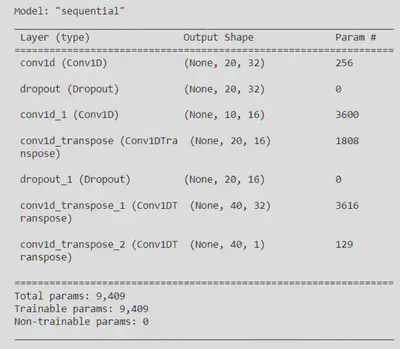
En ce concerne l’architecture de l’Auto-Encodeur Convolutionnel, cette dernière est composée de 2 couche de convolution ainsi que 3 couches de couches de dé-convolution. Entre chaque couche un dropout est appliqué pour prévenir le risque de sur-ajustement du modèle.
Voici le résumé généré par Tensorflow concernant l’architecture du modèle Auto-Encodeur-Convolutionnel :
14.4. Entraînement du modèle
Concernant l’entraînement du modèle Auto-Encodeur Convolutionnel, il est important de noter que puisque l’objectif de l’auto-encodeur est de reconstruire la courbe de charge de base fournie en entrée, nous avons utilisé le jeu de données d’entraînement Xtrain à la fois comme entrée et comme variable cible puisqu’il s’agit dans notre cas d’un mode de reconstruction. Les hyperparamètres de l’entraînement sont les suivants :
— $epoch = 50$
— $batchSize = 128$
— $optimizer = Adam$
— $aeLoss = MSE$
Techniquement, l’objectif recherché est de minimiser l’erreur de reconstruction en fonction d’une fonction de perte. La fonction de perte que nous avons choisi est l’erreur quadratique moyenne $(Mean Squared Error)$. En effet nous voulons davantage pénaliser les valeurs aberrantes étant donné que nous souhaitons apprendre la courbe de consommation de base.
Mean Squared Error - MSE
$\sum_{i=1}^{D}(x_i-y_i)^2$
14.5. Evolution de la fonction de perte
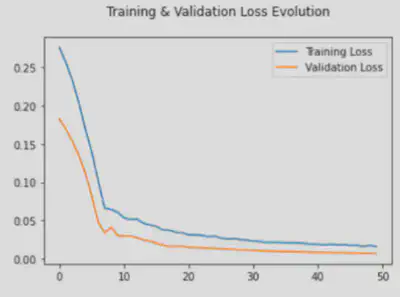
14.6. Visualisation de la reconstruction de la courbe de charge base
Voyons comment notre modèle a reconstruit le premier échantillon. Il s’agit des 40 pas de temps du jour 1 de notre jeu de données d’entraînement.
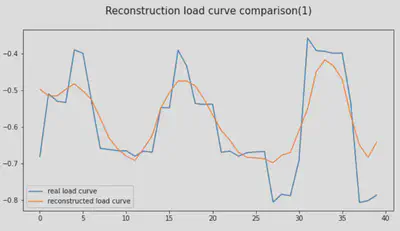
14.7. Détection des anomalies
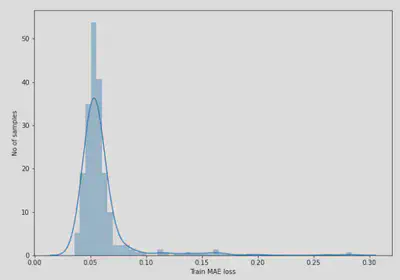
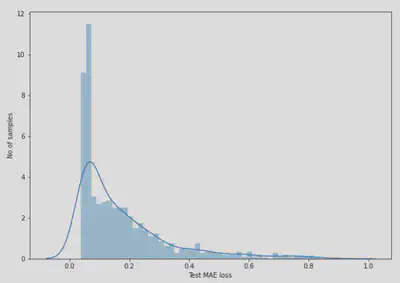
A ce stade, le modèle à appris à reconstruire la courbe de charge de base. Cela signifie que le modèle a appris à modéliser le comportement normal des activités quotidiennes d’un foyer. Sur cette base, la détection des anomalies peut être réalisée en évaluant tout simplement les écarts entre la courbe de charge de base apprise par le modèle et la courbe de charge quotidienne d’un foyer qui comprend des pics d’activité (i.e surconsommation électrique). Cet écart est calculé avec la fonction de perte Mean Absolute Error. Nous avons choisi cette fonction de perte car elle est plus robuste aux données aberrantes ce qui correspond dans notre cas aux anomalies. Sur les différents histogrammes, on voit l’évolution de cet écart pour le jeu d’entraînement et le jeu de test.
Ainsi, pour détecter les anomalies, nous procédons de la manière suivante :
- Calcul de la perte $MAE$ sur les échantillons d’entraînement.
- Identification de la valeur maximale de perte MAE. C’est la plus mauvaise performance de notre modèle en essayant de reconstruire un échantillon. Nous en ferons le seuil (i.e threshold) pour la détection des anomalies.
- Si la perte de reconstruction d’un échantillon est supérieure à cette valeur seuil, alors nous pouvons en déduire que le modèle fait face à un comportement qui ne lui est pas familier. Nous allons étiqueter cet échantillon comme une anomalie
Mean Aboslute Error - MAE
$\sum_{i=1}^{D}|x_i-y_i|$
Évolution de la perte $MAE$ sur l’ensemble de jeu d’entraînement
Évolution de la perte $MAE$ sur l’ensemble de jeu de test
14.8. Post-Processing
Comme évoqué précédemment, la phase de post-processing a pour objectif d’affiner les prédictions. En effet, étant donné que les séquences se chevauchent, il arrive parfois qu’un point de donnée se trouve à la fois dans une séquence prédite par le modèle comme une anomalie et une séquence prédite comme un fonctionnement normal. Par conséquent on se heurte ici un à dilemme. Le point de données en question, est il finalement réellement une anomalie ou non. Pour pallier ce problème le post-processing réalise un vote majoritaire pour chaque point de données se trouvant dans cette situation. Par conséquent si ce dernier apparaît davantage dans des séquences prédite comme anomalie alors, le point de donnée en question sera étiqueté comme une anomalie et inversement. Bien évidemment pour éviter les cas des égalités parfaite, nous avons un nombre de chevauchement de séquences impairs est fixées préalablement lors de la phase de pré-processing.
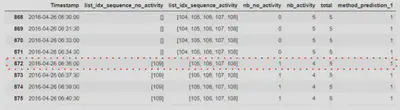
Le but du post-processing est d’affiner les prédictions du modèle car il arrive parfois que un point de donnée se trouve à la fois dans une séquence prédite comme étant une anomalie et inversement.
Par exemple, sur l’image ci-dessus le point de données encadré en rouge correspond à une donnée de consommation à la date du 26 avril 2016 à 06 :36 :00. Ce point de données appartient à plusieurs séquences qui se chevauchent à savoir la séquence n° 109 qui est prédite en non activité et les séquences n° 105, 106, 107 et 108 qui sont prédites comme étant des activités. Ainsi par vote majoritaire, le postprocessing prédit une activité pour cette date. Cela doit correspondre semble correspond à l’heure où la personne se lève le matin avant de se rendre au travail et prend une douche ou bien encore son petit déjeuner.
Ainsi le résultat du post-processing est le suivant
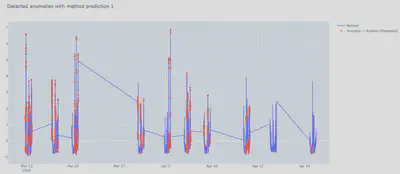
14.9. Pipeline du modèle AEC
- Load dataset
- Convert user input
- Pre-processing (build sequences)
- Build model
- Train model
- Plot Reconstructed curve
- Compute Threshold
- Make predictions
- Detecting activities
- Post-processing (vote majoritaire)
- Plot detected activities
- Evaluate model
- Plot Evaluation model (Matrice de confusion et IoU threshold)
14.10. Evaluation du modèle sur la dataset The Rainforest Automation Energy Dataset
Matrice de confusion
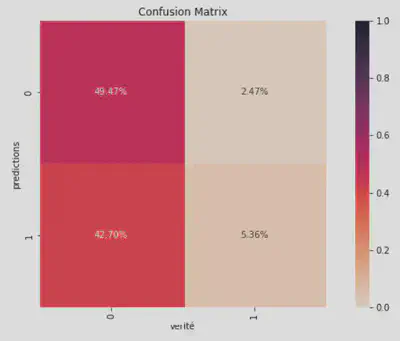
Activité prédite VS Activité réelle
IoU Threshold

14.11. Evaluation du modèle sur la dataset UK-DALE
Pour tester ce modèle nous entraînons l’auto encodeur sur la maison 2 UK-DALE. Afin d’obtenir les résultats détaillés ci-dessous nous utilisons 20% du jeu UK-DALE (soit 28 jours) comme jeu d’entraînement et les 114 jours restants comme jeu de test.
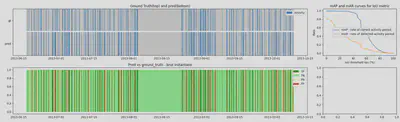
14.12. Futures améliorations possibles
Le modèle Auto-Encodeur Convolutionnel est encore perfectible. En effet, des améliorations sont possibles pour rendre le modèle encore plus performant et surtout plus généralisable. Par conséquent, l’une des améliorations possibles est d’affiner le threshold. Cela consisterait a utiliser différentes stratégies pour le calul du threshold de détection d’activité. Initialement, le threshold correspond à la perte $MSE$ maximale. L’une des stratégie envisageable pour affiner la frontière de décision du modèle est de calculer le quantile plutôt que le “hard maximum” sur le jeu d’entraînement. Cela permet d’attribuer plus de flexibilité au modèle dans le choix threshold qui risque de mal de se généraliser.
Une seconde amélioration consiste à affiner l’architecture de l’auto-encodeur. Une architecture optimale pourrait améliorer les performances de détection d’activité du modèle. Pour trouver l’architecture optimale, il convient de réaliser ce que l’on appelle en machine learning un Neural architecture Search (NAS) qui est une technique d’automatisation de la conception de réseaux neuronaux artificiels (ANN). Il vise à découvrir la meilleure architecture pour un réseau de neurones pour un besoin spécifique. Le NAS reprend essentiellement le comportement du processus d’un humain peaufinant manuellement un réseau de neurones et apprenant ce qui fonctionne bien, et automatise cette tâche pour découvrir des architectures plus complexes. Ce domaine représente un ensemble d’outils et de méthodes qui testeront et évalueront un grand nombre d’architectures dans un espace de recherche en utilisant une stratégie de recherche et sélectionneront celle qui répond le mieux aux objectifs d’un problème donné en maximisant (ou minimisant selon le cas d’usage) une métrique d’évaluation personnalisée. Toutefois, les méthodes NAS explorent de nombreuses solutions potentielles avec des complexités variables et sont donc très coûteuses en calculs. Plus leurs espaces de recherche sont grands, plus il y a d’architectures à tester, entraîner, évaluer. Par ailleurs, ce domaine souffre de plusieurs autres limitations. En effet, il est difficile de savoir comment un modèle potentiel se comportera sur des données réelles. Comme les architectures sont évaluées avec des données d’apprentissage, ces dernières doivent être de bonne qualité si l’on s’attend à un modèle performant sur des données réelles. Il reste nécessaire de définir comment l’algorithme trouvera et évaluera ces architectures. Cette tâche se fait encore à la main et doit être peaufinée. Cependant, le manque de connaissance du domaine ne va pas pénaliser l’efficacité de l’architecture. Cette connaissance est utile pour accélérer le processus de recherche, elle guidera la recherche et ainsi l’algorithme convergera plus rapidement vers une solution optimale.
D’autres paramètres peuvent également être ajustés en plus de ceux directement liés à l’architecture du modèle. Par exemple la méthode d’agrégation des prédictions du modèle repose sur un vote majoritaire, mais on pourrait également jouer sur cet aspect en exigeant par exemple un consensus. De même nous avons posé les bases d’un système d’optimisation des hyperparamètres tels que la longueur des séquences considérées (observation pendant 1h de la courbe de charge vs observation pendant 10 min pour classifier) ou le pas de temps utilisé pour échantillonner le dataframe (1 mesure par seconde ou 1 mesure par minute ?).
Enfin, les changements d’échelle ou d’habitude de consommation peuvent mettre à mal les performances du modèle. Pour s’assurer d’avoir un modèle durable. Une parade possible à se phénomène est d’effectuer des mises à jours fréquentes du modèle, par exemple en attribuant plus de poids aux données récentes. Ainsi des changements d’équipements électriques pourraient être pris en compte dynamiquement par la solution, de même que des changements de mode de vie comme le nombre d’habitants, la saisonnalité…
14.13. Conclusion de l’approche non-supervisée : Auto-Encodeur Convolutionnel
-> Besoin d’un nombre conséquent de données pour apprendre la courbe de charge nocturne (28 jours de données de consommations électrique au minimum)
Avantages
- Rapide à entraîner
- Modèle ajustable
- Généralisable
- Meilleure explicabilité (connaissance du threshold de détection d’activité)
Inconvénients
- Pas facile à déployer (beaucoup de paramètres à choisir)
- Résultats variables : dépend de l’initialisation des couches de l’AEC
- Sensible aux hyperparamètres