Les Modèles Génératifs (Partie 3) | Les Transformers
Les modèle Transformers, la base des modèles de langage sur lesquels reposent les LLM, ont révolutionné le domaine du traitement du langage naturel.
 Image credit: Film Transformer
Image credit: Film TransformerSommaire
- 1. Les transformers
- 2. La tokenization
- 3. Architecture d'un Transformer
- 4. 1er concept: L'encodage positionnel
- 5. 2ème concept: Le mécanisme d'attention
- 6. 3ème concept: L'auto-attention
- 7. Inférence du Transformer
- 8. Les modèles Transformers pré-entraînés en français
- 9. Apprentissage par transfert : Le fine-tuning
1. Les transformers
Aujourd’hui, en machine learning, parmi les architectures les plus courantes et celles qui produisent les performances à l’état de l’art sont basées sur des Transformers et le mécanisme d’attention. En effet, l’architecture « Transformer » s’est imposée comme le modèle de référence pour l’ensemble des champs d’application du NLP (classification de texte, question answering,..). Avant l’arrivée des « Transformers » en 2017, les réseaux RNN étaient utilisés pour comprendre un texte. Ces réseaux RNN prennent en entrée une séquence (une phrase) puis traitent les mots de manière séquentielle c’est-à-dire les uns après les autres. Cela permet au RNN de connaître la position d’un mot dans une phrase. Cependant les RNN ont du mal à gérer de grandes séquences de texte (les paragraphes). Cela signifie que lorsque le réseau a fini de traiter 90% des mots de la longue séquence, ce dernier oublie les mots qu’il a examinés au début de la séquence. A cela s’ajoute un autre problème qui concerne l’apprentissage compliqué des RNN à cause de la disparition du gradient (non-convergence vers le minimum global de la fonction de perte). Aussi, étant donné que les RNN fonctionnent de manière séquentielle, il n’est pas possible de paralléliser les calculs sur plusieurs GPU (carte graphique) pour diminuer le temps d’entraînement du réseau. Cela signifie donc qu’il n’est pas envisageable d’entraîner le réseau RNN sur un grand volume de données. Tous ces problèmes constituent en fait les principales motivations de l’introduction des Transformers. En effet, les scientifiques en imaginant l’architecture « Transformer » ont pu apporter une solution plus efficace que les RNN. Autrement dit, si celle-ci a fait l’objet de notre attention, c’est que ce modèle est à la fois :
- Plus performant que les RNN en termes de résultats pour diverses tâches NLP
- Plus performant que les RNN en termes de rapidité d’apprentissage, car l’entraînement peut être parallélisé
- Dépasse les limitations des RNN en termes de longues dépendances temporelles.
- Une fois pré-entraîné, de façon non supervisée (initialement avec un très large dataset constitué de nombreux documents), il possède une “représentation” linguistique qui lui est propre. Il est ensuite possible, sur la base de cette représentation initiale, de le personnaliser pour une tâche NLP particulière. Il peut être entraîné en mode incrémental (de façon supervisée cette fois) pour spécialiser le modèle rapidement et avec peu de données.
Même si nous pouvons référencer et représenter la signification de chaque mot avec un vecteur, la vraie signification d’un mot repose sur le contexte dans la phrase, car le même mot dans différentes phrases peut avoir des significations différentes.
Les questions qui se posent alors sont : Comment le Transformer gère-t-il l’ordre des mots sans RNN ? Comment le Transformer parvient à modéliser le langage naturel ?
Pour répondre à ces questions, il convient de passer en revue l’architecture d’un Transformer et d’expliquer ce qui se cache derrière le mécanisme d’attention qui constitue la pierre angulaire de l’architecture.
2. La tokenization
Avant de se lancer dans la description de l’architecture du Transformer, il convient d’abord de s’intéresser aux techniques de tokenization. La tokenization est un concept incontournable dans le domaine du traitement automatique du langage naturel (TALN). En effet, pour permettre aux algorithmes d’effectuer des traitements sur le texte qui leur est fourni en entrée, nous avons besoin de découper les phrases en plusieurs éléments (tokens) afin d’obtenir une séquence qui pourra être interprétée et ingérée par les modèles.
Il existe différentes approches pour tokenizer le texte, chacune d’entre elles a des avantages et inconvénients :
Une approche mot par mot : Il s’agit de l’approche la plus intuitive qui consiste à découper chaque séquence (phrase) en mots. Chaque mot emporte une grande quantité d’informations. Cependant deux problèmes se posent, nous avons une énorme quantité de classes (mots) à prédire (une langue = plusieurs millions de mots) et les mots rares ne sont pas bien représentés dans le dataset ou même exclus pour limiter le nombre de mots. Il y a aussi des soucis dans la gestion des mots ‘Hors Vocabulaire’ (OOV : Out of Vocabulary) ce qui mène à une perte d’informations.
Une approche caractère par caractère : A travers cette approche, un caractère correspond à un token. Cette méthode permet de gérer correctement les tokens OOV et de limiter drastiquement le nombre de classes à prédire. Cependant cela a pour conséquence de rallonger très fortement la longueur des séquences à analyser.
Une approche par morceaux de mots : méthode aussi appelée
SentencePieceouSubword Tokenization. Cette approche est utilisée dans de nombreuses méthodes à l’état de l’art (modèles à base de Transformers). Elle consiste à encoder le texte par morceaux de mots. Cela permet de mieux prendre en charge les mots OOV tout en conservant un nombre de classes et une longueur de séquence petite. Il existe plusieurs méthodes afin de déterminer le découpage, la plus connue étant leBPE(Byte Pair Encoding).
L’algorithme BPE consiste à calculer les fréquences de chaque $\text{n-gram}$ (sous-séquence de $n$ éléments construite à partir d’une séquence donnée) de manière itérative. L’utilisateur définit une taille de vocabulaire cible et chaque itération continue de former des combinaisons de tokens afin de réduire la taille du vocabulaire. De manière plus concrète, à chaque passage sur l’ensemble du corpus, les paires sont classées par fréquence d’apparition, chaque paire devenant une unité pour le passage suivant (au premier passage une unité représente 1 caractère, au second passage une unité représente 1 caractère associé au caractère suivant (donc 2 caractères), au troisième passage une unité représente 2 caractères associés au caractère suivant (donc 3 caractères), et ainsi de suite). Finalement, classés par fréquence d’apparition, la liste des sous-mots les plus fréquents dans le corpus est établie. Il s’agit du vocabulaire. L’algorithme BPE est utilisé par les modèles Transformer pour “tokenizer” une phrase.

3. Architecture d’un Transformer
Intéressons-nous maintenant à l’architecture globale du Transformer. Elle est décrite comme ci-dessous :
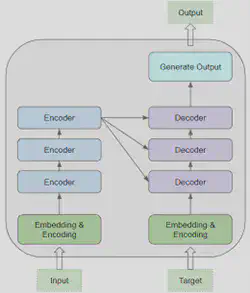
Son architecture est construite comme suit :
Un bloc “Embedding & Encoding” est connecté à l’entrée de la pile d’encodeur et décodeur. Cette couche transforme les mots de la séquence d’entrée en vecteur pour qu’ils soient compris par l’encodeur et le décodeur. Ces derniers pourront alors effectuer des opérations calculatoires sur ces vecteurs pour y déceler les mots de la séquence d’entrée ayant une signification voisine. A cela s’ajoute un encodage positionnel qui permet au Transformer de gérer l’ordre des mots dans une phrase et ainsi comprendre le contexte global de la séquence d’entrée.
Une pile d’encodeurs : Chaque encodeur prenant en entrée la sortie de l’encodeur précédent sauf le premier qui prend en entrée les mots vectorisés et encodés par encodage positionnel.
Une pile de décodeurs : Chaque décodeur prenant en entrée la sortie du décodeur précédent et la sortie du dernier encodeur sauf pour le premier décodeur qui ne prend en entrée que la sortie du dernier encodeur.
En résumé, un Transformer est composé de blocs d’encodeurs et de décodeurs dont chacun possède sa propre matrice de poids. A cela s’ajoute un bloc transformant la séquence d’entrée dans un format qui peut être ingéré par les blocs encodeurs et décodeurs.
Intéressons-nous maintenant à ce que contient un bloc encodeur et décodeur.
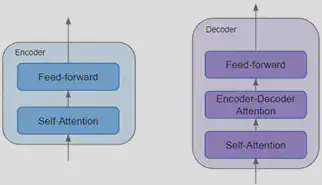
Chaque encodeur contient la couche d’auto-attention qui permet d’examiner de manière sélective chaque mot de la séquence d’entrée. C’est cette couche qui modélise les relations qui existent entre les mots d’une phrase. Enfin, l’encodeur contient également une couche complètement connectée appelée Feed-Forward. Celle-ci a pour but de connecter les couches de réseaux de neurones de chaque encodeur entre elles.
Côté décodeur, ces derniers suivent la même configuration que l’encodeur à savoir une couche d’auto-attention et une couche Feed-Forward. En revanche, le décodeur intègre une deuxième couche d’attention appelée attention encodeur-décodeur qui permet de communiquer au décodeur le degré d’importance qui a été accordé à chaque mot par l’encodeur dans une phrase à l’aide d’un vecteur de contexte.
Le schéma global d’un Transformer peut paraître effrayant, or l’innovation derrière le Transformer se résume en trois concepts principaux :
- L’encodage positionnel
- L’attention
- L’auto-attention
4. 1er concept: L’encodage positionnel
On a vu avant que les RNN comprenaient l’ordre des mots en traitant ces derniers de manière séquentielle mais, que cela les rendait difficiles à paralléliser. Les Transformers contournent ce problème grâce à la technique de l’encodage positionnel.
En entrée, chaque mot est représenté par un vecteur (embedding) de dimension $512$ que l’on note $dmodel$. Une fois que les mots sont transformés en vecteur, le ‘positional encoding’ permet d’encoder l’ordre d’apparition d’un mot dans la séquence d’entrée. Cela donne alors une matrice de même taille que la matrice d’embedding soit $512$ pour sommer les deux matrices colonnes. Cette somme produit donc un vecteur de contexte permettant au Transformer de comprendre le sens du mot dans la phrase. En effet, la signification réelle d’un mot dans une phrase s’établit en fonction de sa position dans la phrase car le même mot peut s’employer de différentes manières dans une phrase.
Prenons l’exemple des phrases suivantes : «Le chat a griffé Arthur» et «Arthur a griffé le chat». Sans l’information de contexte, les deux phrases auraient des imbrications presque identiques. Mais, nous savons que ce n’est pas vrai, certainement pas vrai pour Arthur.
L’incorporation de mots et le codage positionnel produisent un vecteur de mot avec un contexte.
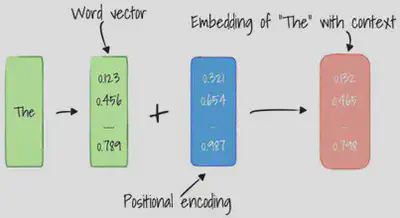
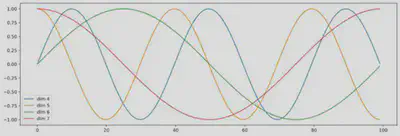
Pour calculer le vecteur de position, plusieurs fonctions sinus et cosinus sont utilisées. Cela permet d’utiliser l’encodeur positionnel pour des phrases de n’importe quelle longueur. La fréquence et le décalage de l’onde sont différents pour chaque dimension, représentant chaque position, avec des valeurs comprises entre $-1$ et $1$.
Cette méthode d’encodage nous permet également de déterminer si deux mots sont proches l’un de l’autre. Par exemple, en référençant l’onde sinusoïdale basse fréquence, si un mot est à « haut » tandis qu’un autre est à «bas», on sait qu’ils sont plus éloignés, l’un situé au début, l’autre à la fin.
5. 2ème concept: Le mécanisme d’attention
Lorsque l’on regarde un match de football à la télévision, on focalise instinctivement notre attention sur le ballon car notre expérience nous a appris que c’est proche du ballon que se trouve l’essentiel de l’information de l’action de jeu en cours. Des systèmes de traduction ou des descriptions d’images parviennent aujourd’hui à simuler ce genre de mécanisme pour améliorer leurs performances. On appelle cela le mécanisme d’attention qui tend à se rapprocher du mécanisme inspiré du fonctionnement du cortex cérébral. Par exemple, dans le cadre d’une traduction automatique, l’attention permet au modèle de « regarder » chaque mot de la phrase d’origine lorsqu’il prend une décision sur la façon de traduire les mots dans la phrase de sortie. La clé des performances du Transformer se trouve dans l’utilisation du mécanisme d’attention. Pour expliquer cela, partons d’abord d’un exemple :
- Le chat a bu le lait car il avait faim
- Le chat a bu le lait car il était sucré
Dans la première phrase, le mot il se réfère à chat. A l’inverse dans la deuxième phrase le mot il fait référence au mot lait. Le rôle de l’attention est donc d’examiner la phrase de manière sélective en trouvant les bonnes associations de mots.
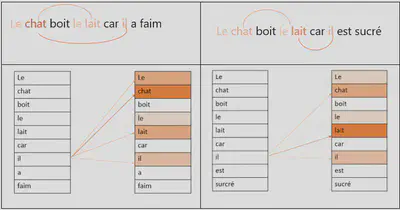
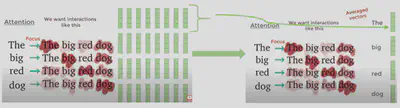
Sur cette carte de chaleur, les couleurs plus prononcées représentent une attention plus élevée.
En fait, pour expliquer de façon imagée, l’attention construit une sorte de carte thermique qui indique sur quel mot de la phrase d’entrée, le modèle doit se concentrer lorsqu’il génère chaque mot en sortie. En entraînant un Transformer, ce dernier apprend à partir de données, sur quel mot il doit porter une attention particulière. Par exemple, l’encodeur communique une information au décodeur comme : “les mots $8$, $11$ et $23$ sont très importants pour donner le sens exact de cette phrase. De plus, il faudra combiner $8$ et $11$, retiens bien ça au moment de décoder la phrase”. En revanche, cela dépend de la position des mots dans la phrase et de leur position les uns par rapport aux autres pour créer un contexte. C’est grâce à l’encodage positionnel que la similarité entre les mots d’un point de vue sémantique peut être vraiment prise en compte. Finalement, l’attention combinée à l’encodage positionnel permet ainsi au modèle de comprendre le sens d’une phrase.
De manière plus concrète, le mécanisme d’attention relie l’encodeur et le décodeur. Son but est de représenter le degré d’attention accordé aux mots à l’aide du vecteur de contexte. Il permet d’informer le décodeur sur quels mots de la séquence d’entrée se rapportent le plus au mot qu’il est en train de générer en sortie, soit qu’ils s’y rapportent comme contexte pour lui donner un sens, soit qu’ils s’y rapportent comme mots “cousins” de signification proche. Le mécanisme d’attention consiste finalement à pondérer l’importance des mots en calculant une loi de probabilité concernant les mots du texte source. Le décodeur se réfère simplement à cette distribution pour prédire le mot suivant qu’il doit générer.
La question qui se pose alors est comment le modèle parvient-il à calculer le degré d’attention à accorder à chaque mot de la séquence. Pour cela, il s’appuie sur la formule mathématique suivante :
$$ \text{Attention(Q, K, V)} = \text{softmax}(\frac{QK^T}{\sqrt{d_k}}) \times V $$Cette formule intègre 3 composants importants qui sont associés à chaque token (mot) de la séquence d’entrée :
- La valeur (value), que l’on note $V$ : ce vecteur contient l’information enrichie par le contexte.
- La clé (key), notée $K$, : elle contient une description de son contenu. Cela fonctionne de manière similaire à un dictionnaire. Pour simplifier à l’extrême avec un exemple, on pourrait imaginer que l’information liée à la clé encodant le “sujet de la phrase” a pour valeur l’information « Thomas Pesquet l’astronaute français »
- La requête (query), notée $Q$, : contient une requête qui sera utilisée afin de rechercher parmi les autres tokens, celui qui est nécessaire pour augmenter le contexte et le niveau d’abstraction.
Dans cet exemple on aurait :
- La clé qui est “Thomas Pesquet”
- La valeur qui est “l’astronaute français”
- La requête qui est “Qui est Thomas Pesquet ?”
Chacune de ces valeurs est calculée et apprise (mise à jour des matrices de poids) lors du processus d’apprentissage, grâce à une matrice de poids. Chaque matrice est distincte, une pour la requête notée $W_Q$, une pour la clé notée $W_K$, une pour la valeur, notée $W_V$.
Afin d’avoir de meilleures performances, il est possible d’utiliser plusieurs têtes d’attention. Nous verrons un peu plus tard l’utilité de l’attention multi-têtes.
Calcul étape par étape de l’attention :
Chaque tête d’attention a ses propres matrices $W_{Q_i}$, $W_{K_i}$, $W_{V_i}$.
- Notons $X$ notre matrice en entrée qui correspond à la matrice de la séquence d’entrée encodée. Pour chaque tête en parallèle :
- On obtient:
- $X. W_{Q_i} = Q_i$ (pour la tête d’attention $i$)
- $X. W_{K_i} = K_i$
- $X. W_{V_i} = V_i$
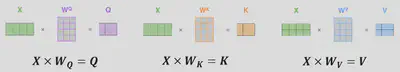
- Calcul des matrices d’attention avec la formule suivante :
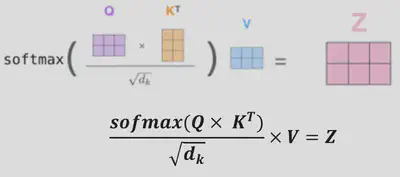
$[Q.K^T]$ est un produit scalaire entre les vecteurs requête $Q$ et les vecteurs clé $K$. Ainsi, plus la clé “ressemblera” à la requête, plus le score produit par $[Q.K^T]$ sera grand pour cette clé. On divise le produit scalaire $[Q.K^T]$ par $8$ (avec $d_k=64$). Il s’agit d’une valeur par défaut qui a été choisie comme tel par les concepteurs du modèle car cela mène à des gradients plus stables et favorise la convergence du modèle vers le minimum global de la fonction de perte lors de son entraînement.
La fonction $softmax()$ normalise les scores pour qu’ils soient tous positifs et qu’ils se somment à $1$. Cela permet donc d’aboutir à une distribution de probabilités qui va encore augmenter la valeur pour les clés similaires aux requêtes, et diminuer celles des clés qui ne ressemblent pas aux requêtes.
Enfin, les clés correspondent à des valeurs. Ainsi, quand on multiplie le résultat généré par la fonction $softmax()$ et par la valeur $V$, les valeurs correspondant aux clés qui ont été “élues” à l’étape précédente sont sur-pondérées par rapport aux autres valeurs.
Le schéma ci-dessous permet d’illustrer cela :
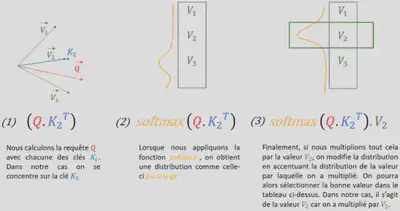
On obtient ainsi le vecteur d’attention (vecteur de contexte) qui prend la forme comme ci-dessous :

- Concaténation de la sortie de chaque tête d’attention : Durant l’étape 2, lorsque le vecteur d’attention est calculé, on constate un petit problème. En effet, chaque vecteur d’attention surpondère sa relation avec lui-même. En l’état, ces vecteurs d’attention sont inutiles car ils ne permettent pas de décrire la relation qu’ils ont avec d’autres mots. Or, pour comprendre le sens de la phrase, nous sommes plus intéressés par les interactions entre les différents mots. C’est pourquoi, nous déterminons huit vecteurs d’attention par mot et nous prenons une moyenne pondérée pour calculer le vecteur d’attention final pour chaque mot. Comme plusieurs vecteurs d’attention sont utilisés, on appelle cela « l’attention à plusieurs têtes » (Multi Head Attention).
Enfin, la dernière étape consiste à concaténer la sortie de chaque tête et multiplier le tout par une matrice de poids $W^O$, qui apprend à projeter le résultat sur un espace de sortie aux dimensions attendues. Cette matrice de poids est entraînée conjointement avec le modèle.
$$ \text{MultiHead(Q, K, V)} = \text{Concat}(\text{head}_1,...,\text{head}_h) \times W_{O} $$ $$ \text{where} \quad \text{head}_i = \text{Attention}(QW_{i}^{Q}, KW_{i}^{K}, VW_{i}^{V}) $$6. 3ème concept: L’auto-attention
Le dernier concept clé du Transformer est une tournure de l’attention appelée « self attention ». Ce mécanisme d’auto-attention est similaire au mécanisme d’attention qui relie l’encodeur et le décodeur. En revanche, au lieu de s’opérer entre les éléments de l’encodeur et du décodeur, ils s’opèrent sur les éléments de l’entrée entre eux ainsi que ceux de la sortie. En effet, plus la représentation interne du langage qu’un réseau de neurones apprend est bonne, mieux le réseau sera performant dans n’importe quelle tâche NLP. Il s’avère que l’attention peut être un moyen très efficace, si elle est activée sur le texte d’entrée lui-même. Cela aide les réseaux de neurones à lever l’ambiguïté des mots, à baliser des parties du discours et à apprendre la sémantique d’une phrase.
7. Inférence du Transformer
Pendant l’inférence, le Transformer n’a en entrée que la séquence d’entrée c’est à dire une phrase. Le Transformer n’a aucune connaissance de la séquence cible qu’il doit prédire. L’objectif du Transformer est de générer la séquence cible à partir de la séquence d’entrée.
La différence avec le modèle Seq2Seq est qu’à chaque pas de temps, l’intégralité de la séquence de sortie générée est réalimentée plutôt que simplement le dernier mot.
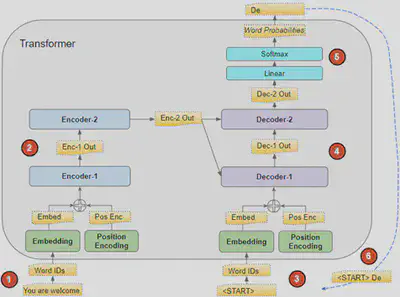
Le flux de données pendant l’inférence est comme suit :
- Après avoir été découpée en petits segments (token) par le tokenizer, la séquence d’entrée est transformée en vecteur avec l’encodage positionnel. Ensuite, ce vecteur est transmis à l’encodeur.
- La pile d’encodeurs réalise ses opérations en pondérant chaque token et ainsi calcule le vecteur de contexte.
- Le token
[START]est fourni au décodeur. Il s’agit d’une séquence vide et il est converti en Embeddings (avec l’encodage positionnel). - La pile de décodeurs effectue ses opérations en prenant en compte la représentation linguistique encodée par la pile des encodeurs contenue dans le vecteur de contexte. Il produit alors une représentation codée de la séquence qu’il va générer.
- La couche $softmax$ convertit la représentation en probabilités de mots et génère une séquence de sortie
- Nous réalimentons le décodeur avec le dernier mot de la séquence de sortie qu’il vient de prédire. Ce mot est ajouté en deuxième position de la séquence d’entrée du décodeur. Ainsi le décodeur reçoit le token
[START]et le premier mot qu’il vient de générer. - Ensuite, on revient à l’étape trois et on répète ce processus jusqu’à rencontrer le token fin de phrase
[CLS]
En conclusion, les Transformers ont rendu possible l’utilisation de modèles pré-entraînés. Ces derniers ont permis des avancées notables pour de nombreuses tâches de NLP. Par ailleurs, avec la prise en compte du contexte dans les représentations vectorielles, ils ont permis une meilleure prise en charge de la polysémie et donc l’obtention de modèles plus efficaces et plus fins. Les modèles pré-entraînés ont ce grand avantage d’avoir une représentation linguistique complète capable de faire face aux spécificités et aux particularités de la langue sur lesquelles ils ont été pré-entraînés.
8. Les modèles Transformers pré-entraînés en français
8.1 Le modèle CamemBERT
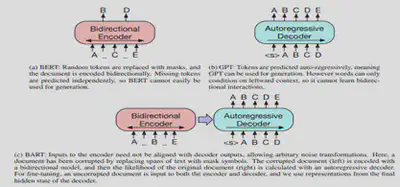
Le modèle CamemBERT est la version française du modèle BERT, pré-entraîné sur un large corpus français de 138 GB. Ce dernier repose sur une architecture « Transformer » de type BERT. BERT est l’un des modèles basés sur des Transformers le plus populaire. Il utilise un tokenizer « Sentence Piece » qui découpe une phrase en plusieurs segments de phrase à l’aide de l’algorithme Byte Pair Encoding. Pour apprendre à modéliser la langue française, le modèle a été entraîné à prédire des mots préalablement masqués dans une phase. Ce modèle est particulièrement adapté pour la tâche de synthèse extractive.
Exemple :
[CLS]indique un début de séquence[SEP]une séparation, en général entre deux phrases dans notre cas.[MASK]un mot masqué qui correspond au mot à prédire
La séquence d’entrée suivante a été volontairement supprimée d’un mot, le mot « masqué », et le modèle va apprendre à prédire ce mot masqué.
- Input =
[CLS]l’homme est allé[MASK]magasin[SEP] - Input =
[CLS]l’homme est[MASK]au magasin[SEP]
8.2 Le modèle mBART’hez
Le modèle BART’hez est la version française du modèle BART, pré-entraîné sur un large corpus français de 120 GB. Ce dernier repose sur une architecture auto-encodeur basée sur des Transformers. Il peut être considéré comme un mélange entre BART et CamemBERT. En effet, l’architecture BART utilise un encodeur de type BERT, ce qui permet d’extraire le contexte dans les deux directions, la sortie de cette première partie est envoyée dans un décodeur autorégressif (un GPT constitué uniquement d’un décodeur) afin de prédire le token suivant. Pour apprendre à modéliser le langage naturel, le modèle a été entraîné à débruiter du texte précédemment altéré avec une fonction arbitraire (permuter les mots, masquer un mot, supprimer un mot, …). Ce modèle est particulièrement efficace pour faire de la génération de texte (Sequence To Sequence).
Etant donné ses bonnes capacités à générer du texte, ce modèle sera utilisé pour la tâche de résumé abstractif.
Au-delà du fait que les deux modèles reposent sur une architecture à base de Transformer, il existe plusieurs points communs entre ces deux modèles qui sont les suivants :
- Utilisent le mécanisme d’attention pour analyser de manière sélective la séquence d’entrée (une phrase) et comprendre la sémantique de celle-ci.
- Capables de modéliser la langue française et d’avoir une connaissance fine de la grammaire française.
- Peuvent être adaptés pour réaliser différentes tâches NLP :
- Classification de texte
- Traduction
- Comparer le sens de deux phrases et dire si elles sont équivalentes
En revanche, à la différence de BERT qui utilise un modèle de type Transformers bidirectionnels (analyse la séquence d’entrée dans les deux 2 sens gauche et droite), les modèles GPT sont basés sur des Transformers left-to right. GPT est un modèle constitué uniquement de décodeurs. Chaque cellule de Transformer ne pose son attention que sur celles qui sont à sa gauche. A la différence de l’encodeur, le décodeur est autorégressif, c’est-à-dire qu’en plus de prendre en entrée les données, il a aussi en « input » les différentes valeurs précédemment générées.

9. Apprentissage par transfert : Le fine-tuning
Pour spécialiser le modèle CamemBERT par exemple sur la tâche de résumé extractif, il est nécessaire de réaliser un fine-tuning sur ce dernier afin de le rendre performant sur cette tâche.
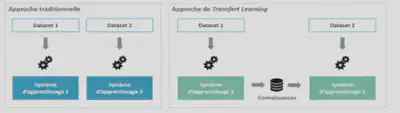
L’apprentissage par transfert (Transfert Learning en anglais) se produit lorsqu’un modèle développé pour une tâche est réutilisé pour travailler sur une deuxième tâche. Le réglage fin (fine-tuning en anglais) est en fait une approche de l’apprentissage par transfert.
Dans un Transfer Learning, nous entraînons le modèle avec un ensemble de données et ensuite, nous entraînons le même modèle avec un autre ensemble de données qui a une distribution de classes différentes que dans l’ensemble de données d’entraînement. Cette technique permet de transférer la connaissance acquise sur un jeu de données “source” pour mieux traiter un nouveau jeu de données dit “cible”. Le Transfer Learning peut s’expliquer intuitivement à travers un exemple simple : imaginons une personne qui veuille apprendre à jouer du piano, elle pourra plus facilement le faire si elle sait déjà jouer de la guitare. La personne pourra capitaliser sur ses connaissances musicales déjà acquises dans la pratique du piano pour apprendre à jouer un nouvel instrument.
Dans un Fine-tuning, qui est une approche de Transfer Learning, nous avons un ensemble de données avec lequel nous réalisons 90% de l’entraînement du modèle. On obtient ainsi un modèle pré-entraîné. Ensuite, nous terminons l’entraînement du modèle à savoir les 10% restants avec un autre dataset spécifique à la tâche sur laquelle le modèle doit performer. Le fine-tuning a pour but d’ajuster très finement les poids des dernières couches du réseau de neurones (les poids des précédentes couches sont gelés) pour pouvoir affiner le modèle sur une tâche NLP bien spécifique. En effet, le taux d’apprentissage choisi pour un fine-tuning est plus faible que celui d’un entraînement classique de manière à minimiser les impacts sur le poids des couches de réseaux de neurones déjà ajustées.